.jpg)
정처기
Table of Content

1. 릴레이션(테이블)과 관련된 것들

•
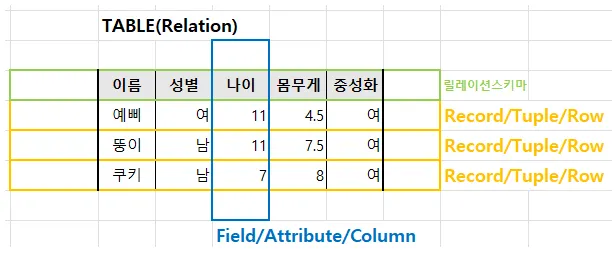
릴레이션 Relation = Table
◦
Field / Attribute / Column : 이름,성별,나이,몸무게,중성화여부
▪
필드, 열 Field = 애트리뷰트 Attribute = Column
•
디그리 Degree = 차수 = 행의 갯수(속성 갯수) = 1개이상 필수
◦
Degree : 5개
▪
열의 수 → 차수 . 속성(Attribute)의 수
◦
Record / Tuple / Row : [여,11,4.5,여] , [뚱이,남,11,7.5,여], [쿠키,남,7,8,여]
▪
튜플, 행 Tuple = Row, Record
•
카디널리티 Cadinality = 기수 = 데이터의 갯수 = 0이 될 수 있음(데이터는 없을 수 있음)
◦
Cardinality : 3개
▪
행의 수 → 기수. 튜플(Tuplu)의 수
▪
여기서 4개가 아닌 이유는 연두색 부분은 릴레이션스키마 부분 노란색은 릴레이션 인스턴스 부분이므로
▪
카디널리티는 튜플의 개수 만 의미한다. 즉 릴레이션 스키마를 제외한 릴레이션 인스턴스 부분만 해당

•
릴레이션에서 튜플,속성 등의 무순서성은 관계형 데이터베이스의 중요한 특성 중 하나
•
튜플, 어트리뷰트는 특정한 순서 없이 존재하며, 데이터의 의미는 각 튜플 간의 관계에 의해 정의됨
•
id로 순서가 있는 것 처럼 착각 할 수 있지만, 주키(Primary Key)는 개발자가 효율적으로 관리하기 위한 용도의 인덱스 역할일 뿐 실제로는 순서가 없는 무순서성을 가진다.

•
카디널리티 C로 그리는것을 기억 = 각 행(Row=Data)들을 나타내는 것이므로

•
속성의 범위, 집합을 도메인이라 한다.(성별 = 남/여 2개와 같이)
2. 관계대수 vs 관계해석
구분 정리 필요
•
관계대수 = 절차
◦
기존 릴레이션(테이블)들로부터 새로운 릴레이션을 생성, 유도하는 절차적 언어 문법
◦
수학적 기호, 연산자
◦
내부적인 처리 연관
◦
데이터 저장, 처리 방법 고려
1. 순수 관계 연산자
▪
SELECT (σ 시그마 / 튜플을 검색)
▪
PROJECT (π 파이 / 속성을 검색)
▪
JOIN (▷◁ / 2개의 릴레이션을 하나로 합침)
▪
DIVISION (X ⊃ Y에서 S가 가진 속성을 제외한 R의 속성)
2. 일반 집합 연산자
▪
UNION
▪
INTERSECTION
▪
DIFFERENCE
▪
CARTESIAN PRODUCT (컬럼 합, 로우 곱)
•
관계해석 = 비절차
◦
사람이 이해할 수 있는 비절차적 질의 언어
◦
원하는 정보가 무엇 이라는 것만 정의
◦
외부적인 처리 연관
◦
내부구조, 처리방법 알 필요 없음
▪
튜플 관계 해석
▪
도메인 관계 해석
▪
∀ : for all
◦
수학의 프레디킷 해석에 기반
◦
Codd가 수학의 술어 해석에 기반을 두고 관계 데이터 베이스에 적용할 수 있도록 설계하여 제안
◦
릴레이션을 정의하는 방법을 제공
•
두방법 모두 관계 데이터베이스 처리하는 기능과 능력면에서 동등하다.

•
각 연산자 종류, 관계 대수, 관계 해석별로 알아 둘 필요 있음
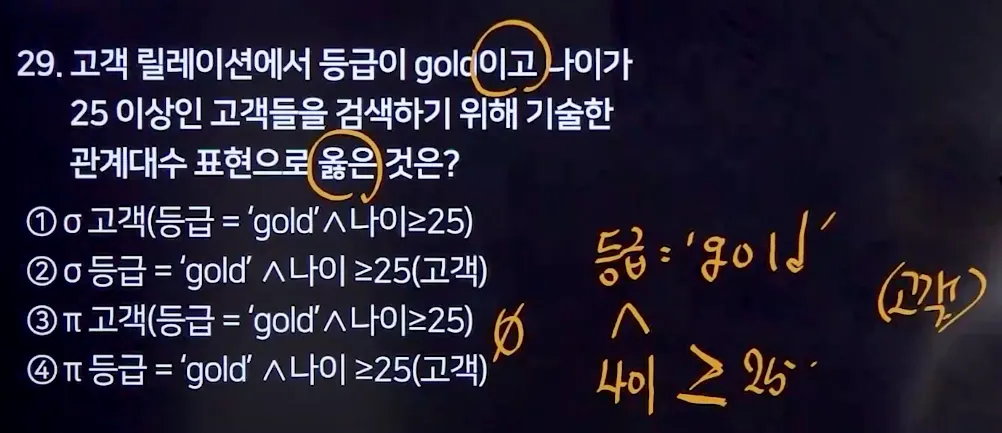
•
각 연산자 기호도 알아야 함


•
관계대수식 관계해석식으로 서로 해석하는 방법 이해
관계해석식으로 서로 해석하는 방법 이해Related Posts
Search








.jpeg&blockId=f8f07b62-00c1-4de1-b1b4-25f6fff4ebc2)