

프로젝트 기획 배경 설명 (30초)
•
해당 프로젝트를 어떠한 배경과 당위성으로 기획하게 되었는지 설명해주세요.
•
“현실에서 어떠한 문제를 발견하여 어떤 기술을 활용하면 이 문제를 해결할 수 있을 것 같았다.”
시연 영상 재생 (1분)
•
서비스의 핵심이 되는 기능만 시연해 주세요. 즉, 회원가입, 로그인 과정 등은 생략해도 됩니다.
•
서비스 시연에는 변수가 많습니다. 가능한 녹화 영상을 활용하여 발표를 진행해주세요.
아키텍처 설명 및 기술 도입 배경 (2분)
•
서비스가 어떤 구조를 갖고 있는지, 주요 기능을 구현하기 위해 어떤 기술을 썼는지 설명하는 시간입니다.
•
아키텍쳐 및 도입한 기술을 설명하실 때는 반드시 의사결정 과정을 설명해 주세요.
스프링부트- MySQL 데이터베이스를 기반으로 하고있습니다. DB는 AWS RDS 환경으로 구축되어 있습니다.
추가적으로 카프카 레디스는 동시성 제어를 위하여 있습니다.
엘라스틱서치는 검색 엔진 기능 역할을 위해 별도 EC2 서버에 Logstash와 KIbana와 함께 구축되어 있습니다. MySQL로부터 도서 데이터를 동기화 하고 있습니다.
프로젝트의 CI/CD 및 소프트웨어 아키텍처에 대해 안내해 드리겠습니다.
저희 팀은 Github Action, AWS의 S3와 Codedeploy로 CI/CD 파이프라인을 구축했습니다.
이를 통해, Github의 main 브랜치로 pull request가 이루어지면 자동으로 AWS EC2 서버로 코드가 배포되는 시스템을 갖추었습니다.
CI/CD 시스템 선택에 있어, 저희는 Jenkins와 GitHub Action 중 고민 끝에 후자를 선택했습니다. Jenkins는 강력한 맞춤 설정이 가능하지만 별도의 서버 유지 및 AWS와의 통합을 위한 추가 작업이 필요한 반면, GitHub Action은 AWS와의 통합이 용이하고 관리가 더 간단하여 개발자가 더 쉽게 작업할 수 있는 장점이 있습니다.
다음으로 저희 소프트웨어 아키텍처를 설명하겠습니다.
클라이언트의 요청이 들어오면 ELB(ALB)가 이를 받아서 HTTP 프로토콜을 사용하는지 확인하고, 필요한 경우 HTTPS로 리디렉션합니다.
안전한 HTTPS 프로토콜을 사용할 경우 요청은 메인 서버로 전달되며, 이 서버는 요청을 적절히 분산하여 처리합니다.
특히 대규모 트래픽을 처리해야 하는 책 나눔 서비스 같은 경우, 마이크로서비스 아키텍처를 적용하여 요청을 처리합니다. 이는 카프카를 통해 이벤트 기반으로 데이터를 처리하고, 레디스의 분산 락을 활용해 동시성을 제어함으로써 효율적인 서비스를 제공합니다. 이후 메인 서비스는 이벤트 서버의 결과를 비동기적으로 받아 클라이언트에게 전달합니다.
저희가 카프카를 책나눔 서비스에 적용한 이유로는 대규모의 데이터 처리와 높은 처리가 필요하였기 때문입니다. RabbitMQ는 높은 메시징 라우팅 기능을 가지고 있지만 카프카는 그 보도 더 많은 양의 메시징 처리를 가능하게 해줍니다.
REDIS
ActiveMQ는 JMS를 지원하지만 카프카가 대용량 처리에서는 더 우수합니다. ZeroMQ는 경량이고 빠르지만 내구성과 데이터 저장 측면에서 카프카가 더 앞섭니다. 마지막 Amazon SQS는 오픈소스인 카프카에 비하여 대용량 처리 비용이 너무 많이 발생합니다. 이러한 이유로 저희는 카프카를 선택하였습니다.
기술적인 도전 및 트러블 슈팅 (3분 30초)
•
서비스 개발 기간 동안 가장 기술적으로 어려웠던 문제를 어떤 방법으로 해결했는지 설명하는 시간입니다.
•
여러분이 어떤 문제를 얼마나 논리적으로 해결을 했는지 정리해 주세요!
◦
데이터베이스와 애플리케이션 레이어에서 각각 두 가지 방법을 적용하여 동시성 문제를 해결했으며, 그중에서도 비관적 락이 가장 우수한 성능을 보였음을 확인했습니다.
그 과정에서 카프카를 이용하면 이러한 문제를 구조적으로 해결할 수 있다는 사실을 발견하고 카프카를 도입했습니다. 카프카의 단일 파티션과 단일 컨슈머 모델을 사용하여 동시성 문제를 해결할 수 있었지만, 다수의 서버가 작동하는 분산 환경에서는 파티션들이 병렬로 작업을 수행함에 따라 여전히 동시성 문제가 발생했습니다. 그럼에도 불구하고 카프카의 병렬 처리 능력과 마이크로서비스 아키텍처의 확장성은 포기할 수 없는 장점들이었습니다. 결국 우리 팀은 이 문제를 카프카 자체로 해결하기보다는 다른 방법을 모색해야 한다고 결론지었습니다.
이에 따라 분산 서버 환경에서는 데이터베이스나 애플리케이션 수준의 락보다는 분산락이 더 적절하다는 사실을 깨달았습니다.
결국 우리는 레디스 분산락을 도입하여 동시성 제어 문제를 해결했습니다. 복수의 파티션이 동시에 병렬 처리를 하는 상황에서 다시 동시성 문제가 생겼을 때, 레디스의 분산락 기능을 활용해 이를 해결할 수 있었고, 이를 통해 각각의 마이크로서비스 아키텍처의 확장성을 유지할 수 있는 이점을 확보했습니다.
검색 1건 ~풀텍→엘라 해보면서 변화 과정 정리추가
성능개선 사항 (2분)
•
응답속도지연 등 서비스시 문제점과 이를 개선한 이야기를 설명하는 시간입니다.
•
자랑할 만한 “숫자” 혹은 “그래프”가 있다면 마음껏 발표에 녹여주세요!
•
성능개선이 아니더라도, 테스트코드 등 안정적인 서비스를 위해 적용한 내용을 추가하셔도 좋습니다.
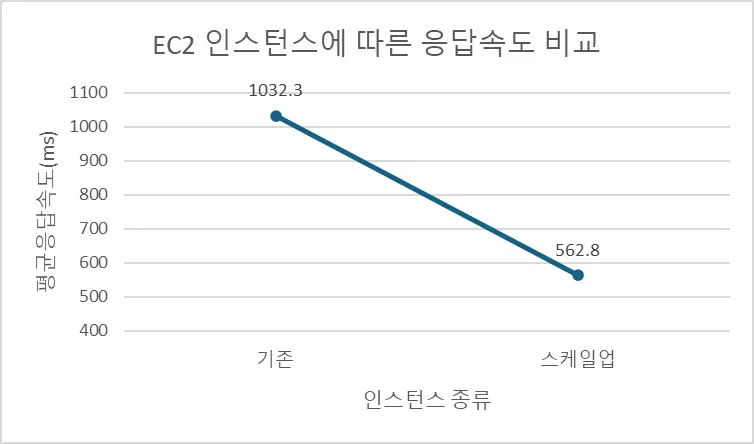
카프카 다중 파티션 및 레디스 분산락을 적용한 책 나눔 서비스에 대해 100건의 요청으로 성능 테스트를 실시한 결과 평균 응답 시간이 1032ms로 측정되어 성능 개선이 필요하였습니다.
이를 위해 두 가지 방법으로 서버를 최적화 하였습니다.
첫 번째 방법으로 서버 인스턴스를 t2.micro에서 더 높은 사양으로 업그레이드 하여 스케일업을 진행하였습니다. 테스트 결과 평균 응답 시간을 563ms로 단축시켜서 약 45%의 성능 향상을 이루었습니다.
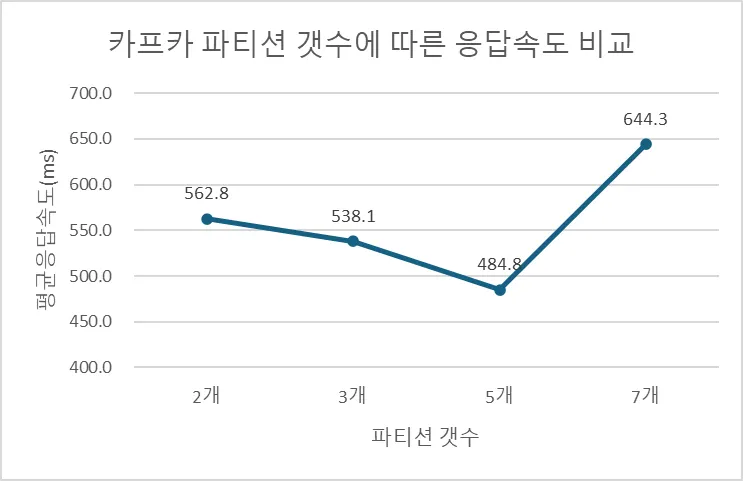
두번째 방법으로는 카프카의 파티션을 기존 2개에서 시작하여 3개, 5개, 7개로 점진적으로 늘려 테스트해 보았습니다. 테스트 결과, 파티션 수가 5개일 때 평균 응답속도가 485ms로 가장 우수하였습니다. 파티션이 7개인 경우 시스템 리소스를 과다하게 사용하여 성능 저하를 일으킨 것으로 보입니다.
최종적으로 서버 스케일업과 카프카 파티션 수 조정을 통해 원래 성능 대비 112.9% 개선된 성능을 달성하였습니다.
아래자료들은 발표자료 만들때 넣을거임
세팅 | 응답속도(ms) | 성능개선 |
기존(t2.micro / 파티션 2개) | 1032.3 | 0.0% |
(t3.micro / 파티션 2개) | 562.8 | 45.5% |
(t3.micro / 파티션 5개) | 484.8 | 53.0% |
서버명 | 인스턴스 |
Team258_MainServer1 | c5.large |
Team258_MainServer2 | c5.large |
Team258_EventApplyServer1 | c5.xlarge |
Team258_EventApplyServer2 | c5.xlarge |
Team258_KafkaServer | c5.2xlarge |
Team258_RedisServer | c5.2xlarge |
검색 1건
테스트를 어떤것들을 했엇고,