

MySQL DB의 데이터와 Elasticsearch 데이터는 동기화로 일관성을 유지해야 한다.
기존 MVP 기능으로 도서의 정보를 변경하는 부분들이 있습니다. 특히 Elasticsearch와 연결된 도서 목록에서 사용자는 도서 대출, 도서 대출 예약을 진행 할 수 있습니다.
사용자가 도서 대출을 진행하면 도서의 대출 가능 여부를 알 수 있는 Status 컬럼은 POSSIBLE에서 IMPOSSIBLE로 변경됩니다. 해당 기능은 HTML의 Ajax HTTP 요청을 통해 MySQL DB에 있는 대상 book_id의 도서의 상태를 즉시 변경하지만, Elasticsearch는 MySQL의 DB를 Logstash로 가져와서 인덱싱하기 때문에 이 과정에서 새로 목록을 불러와야 할 필요성이 있습니다.
Logstash의 데이터 변경 추적 설정 필요성
기존 Logstash를 통해 MySQL의 DB를 전달하여 색인하는 부분입니다. 709만개의 도서 데이터를 한번에 읽어오는 과정에서 JVM의 메모리 부족 현상이 발생하여 200만개씩 메모리에 로드하고 Elasticsearch로 전달하도록 구성되어있습니다.
# sample.conf
input {
jdbc {
jdbc_connection_string => "jdbc:mysql://localhost:3306/team258"
jdbc_user => "inyongkim"
jdbc_password => "1234"
jdbc_driver_library => "/Users/inyongkim/.gradle/caches/modules-2/files-2.1/mysql/mysql-connector-java/8.0.25/f8b9123acd13058c941aff25f308c9ed8000bb73/mysql-connector-java-8.0.25.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_paging_enabled => true
jdbc_page_size => 2000000 # 페이징 크기를 조정하세요.
statement => "SELECT * FROM book"
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "book"
document_id => "%{book_id}"
}
}
Java
복사
하지만 이 부분에서 설정의 문제점이 있습니다.
•
최초 실행 1회 이후로 데이터를 전달하고 해당 소스는 종료됨
•
MySQL DB의 변경사항이 생기면 수동으로 해당 파일을 다시 실행시켜 주어야 업데이트가 됨
•
다시 한번 200만개씩 총 709만개를 돌면서 업데이트가 아닌 모든 정보를 덮어쓰는 형태
최초의 전체 709만개 도서 데이터 전달은 기본적으로 실행되어야 하는데 지속적으로 어떤 도서의 정보 업데이트에 대한 별도 동기화 처리가 필요했습니다.
Logstash의 tracking_column을 이용한 변경 추적

공식 문서에 따라서 tracking_column을 통해서 특정 컬럼의 값이 변경되는 것을 추적할 수 있고, Elasticsearch에 변동된 행만을 업데이트 할 수 있는 방안이 있었습니다.
아래와 같은 방식으로 설정 실행 파일을 수정했으며 데이터베이스를 일부 수정(Book 테이블의 Timestamped 테이블 상속)해보았습니다.
•
MySQL 도서 데이터에 modified_at 이라는 컬럼을 통해서 업데이트된 시점을 기록하도록 변경
•
Logstash는 MySQL의 modified_at 이라는 컬럼을 추적하도록 설정(tracking_column)
•
schedule을 통해서 Logstash의 데이터 전달이 주기적으로 실행되도록 설정
◦
"* * * * *" 는 1분 주기를 말함, cron 표현식에 따라 시간을 조절 할 수 있습니다.
아래와 같이 주기를 1분으로 설정하여 데이터를 가져왔습니다.
# sample.conf
input {
jdbc {
jdbc_connection_string => "jdbc:mysql://localhost:3306/team258"
jdbc_user => "inyongkim"
jdbc_password => "1234"
jdbc_driver_library => "/Users/inyongkim/.gradle/caches/modules-2/files-2.1/mysql/mysql-connector-java/8.0.25/f8b9123acd13058c941aff25f308c9ed8000bb73/mysql-connector-java-8.0.25.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_paging_enabled => true
jdbc_page_size => 2000000 # 페이징 크기를 조정하세요.
schedule => "* * * * *"
statement => "SELECT * FROM book WHERE modified_at > :sql_last_value"
use_column_value => true
tracking_column => "modified_at"
tracking_column_type => "timestamp"
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "book"
document_id => "%{book_id}"
action => "update"
doc_as_upsert => true
stdout {
codec => rubydebug
}
}
}
Java
복사
업데이트 감지에서의 페이징은 불필요
데이터의 업데이트를 감지하는 것에 있어서 페이징으로 분리할 필요가 없었습니다. 오히려 200만개의 데이터 내에서만의 변경을 감지하는 루프가 돌고 있어서 그 외 데이터의 변경을 감지못하는 현상이 발생했습니다. 아래 사진을 통해서도 계속해서 200만개 이내의 데이터만 조사하고 있는 것을 볼 수 있습니다.
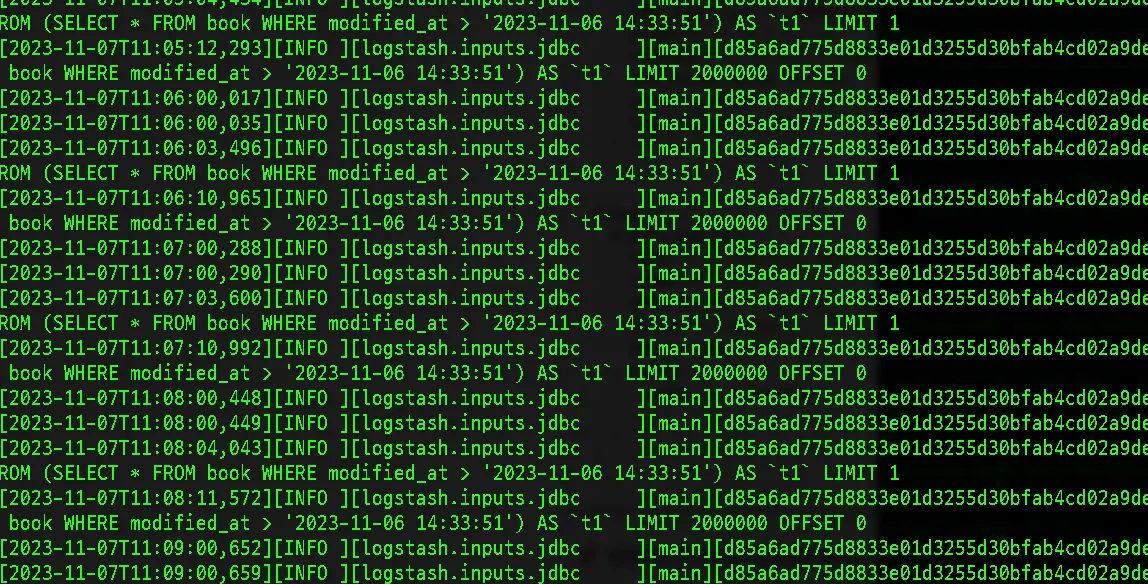
따라서 업데이트를 감지하고 전달하는 input/output 블록에서는 페이징을 삭제하여 전체 데이터를 감지하도록 수정했습니다.
초기 데이터 로딩과 주기적인 업데이트가 동시에 필요함
위 설정 파일을 실행하면 Logstash는 업데이트에 대한 감지와 관련된 주기적인 활동만 진행했습니다.
하지만 제가 원하는 수행 목표는 다음과 같습니다.
•
첫 서버 실행시 709만개의 데이터를 전달해야 함
•
즉시(또는 주기적으로) 업데이트된 데이터를 감지하고 전달해야 함
•
위 두개의 활동은 Logstash가 실행 되는 시점에 동시에 작동해야함
여기서 위 두개의 각기 다른 목적을 가진 소스코드를 동시에 넣을 수 있다는 것을 알게되었습니다. 아래와 같이 블록으로만 구분하면 첫번째 input/output 블록과 두번째 input/output 블록은 동시에 시작됩니다.
# sample.conf
# 초기 데이터 색인을 위한 input/output 블록
input {
jdbc {
jdbc_connection_string => "jdbc:mysql://localhost:3306/team258"
jdbc_user => "inyongkim"
jdbc_password => "1234"
jdbc_driver_library => "/Users/inyongkim/.gradle/caches/modules-2/files-2.1/mysql/mysql-connector-java/8.0.25/f8b9123acd13058c941aff25f308c9ed8000bb73/mysql-connector-java-8.0.25.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_paging_enabled => true
jdbc_page_size => 50000 # JVM 메모리 부하 감당할 수 있는 정도로 설정
# schedule => "* * * * *" # 서버실행시 1회만 실행되도록 주기 제거
statement => "SELECT * FROM book"
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "book"
document_id => "%{book_id}"
}
}
# 주기적인 업데이트를 위한 input/output 블록
input {
jdbc {
jdbc_connection_string => "jdbc:mysql://localhost:3306/team258"
jdbc_user => "inyongkim"
jdbc_password => "1234"
jdbc_driver_library => "/Users/inyongkim/.gradle/caches/modules-2/files-2.1/mysql/mysql-connector-java/8.0.25/f8b9123acd13058c941aff25f308c9ed8000bb73/mysql-connector-java-8.0.25.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_paging_enabled => true
schedule => "* * * * *" # 기본 1분
statement => "SELECT * FROM book WHERE modified_at > :sql_last_value"
use_column_value => true
tracking_column => "modified_at"
tracking_column_type => "timestamp"
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "book"
document_id => "%{book_id}"
action => "update"
doc_as_upsert => true
}
}
Java
복사
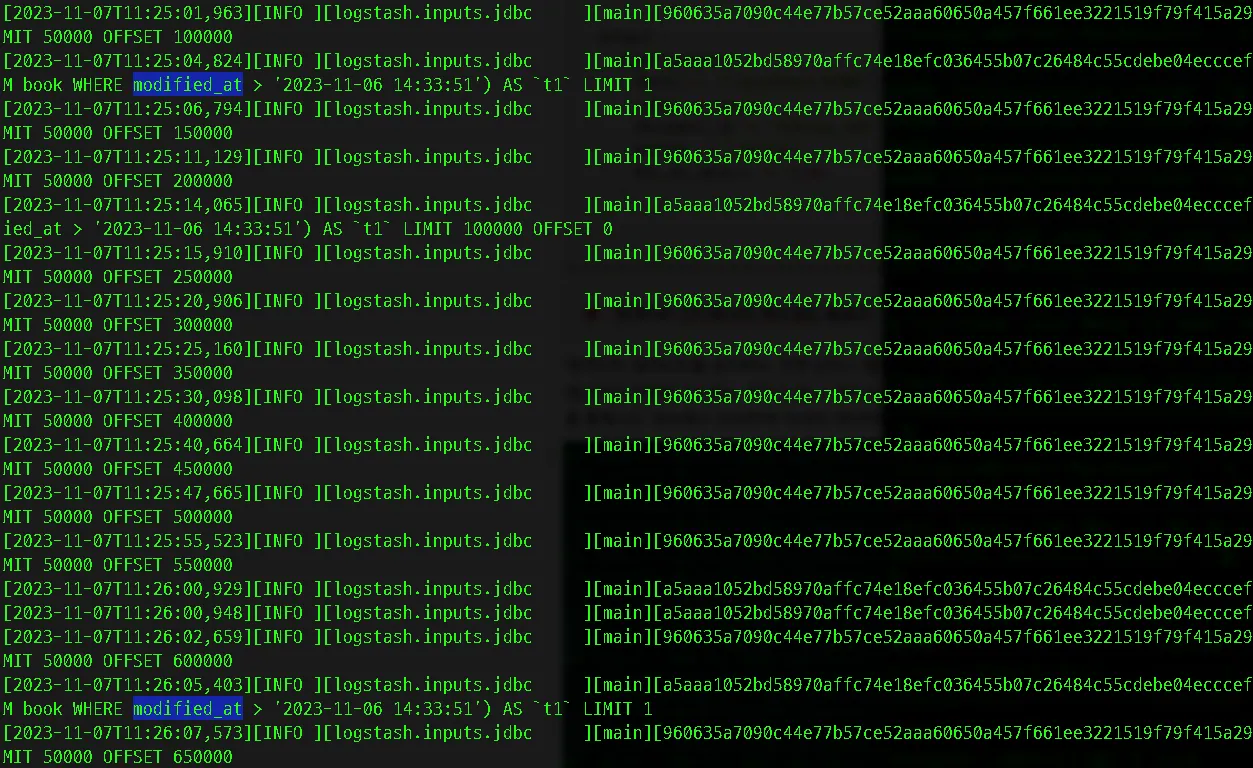
위 사진과 같이 서버 실행 시 아래 두개가 동시에 실행되고 있습니다.
•
50000개씩 709만개의 전체 데이터를 색인하는 최초 1회 데이터 로딩 및 전달이 실행(주기 없음)
•
동시에 modified_at컬럼을 통해서 변경사항을 추적하고 전달하는 블록이 실행(1분 주기)
또한 709만개의 모든 데이터가 전달된 이후로는 업데이트와 관련된 input/output 블록은 지속하여 실행되고 있음을 확인 할 수 있습니다.
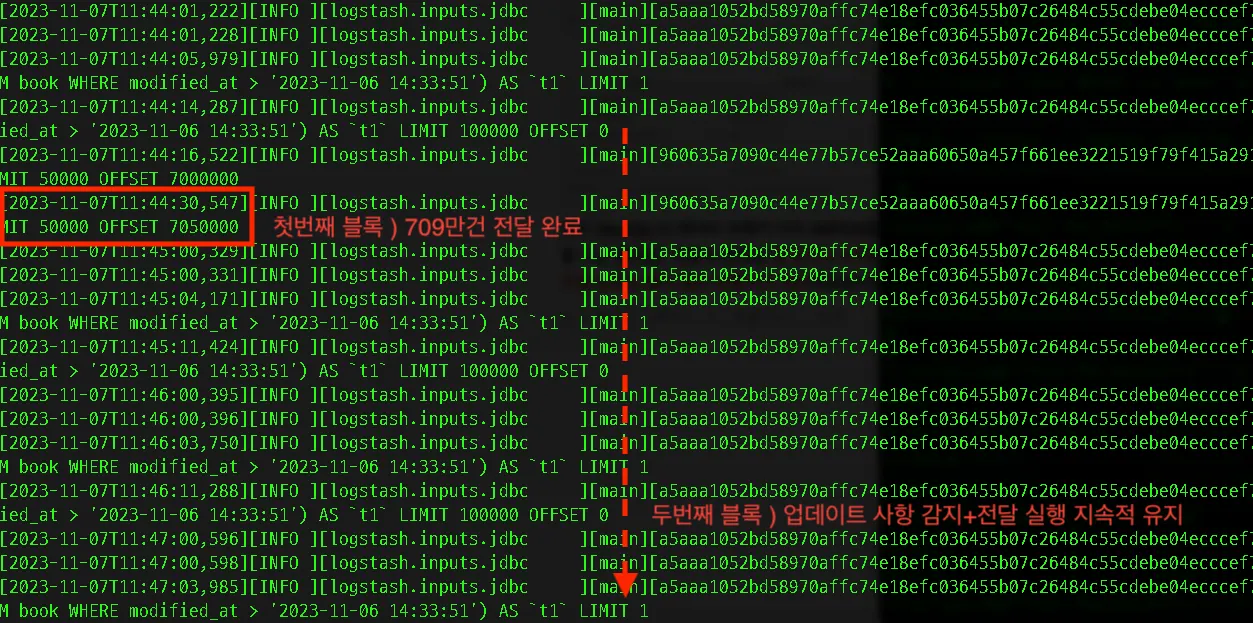
MySQL DB 업데이트 시점과 Logstash의 감지 주기의 시간 차이로 인한 문제점
schedule 에서 표현되는 "* * * * *" 는 1분 주기를 말합니다. 이는 cron 표현식으로 시간을 조절 할 수 있습니다. 하지만 거의 즉시 업데이트를 반영하고자 1초, 또는 0.1초 단위로 업데이트를 감지하도록 변경하고 싶었지만 해당 표현식으로는
이는 Elasticsearch를 통해 뷰 페이지를 반환하고 있는 점에서 MySQL과 Elasticsearch의 데이터간의 일관성을 유지 못하는 1분의 공백의 문제가 발생하고있습니다.
데이터의 변경 흐름은 다음과 같습니다.
1.
(시작) Elasticsearch로부터 도서의 정보가 뷰 페이지에 나타남
2.
→ 도서를 대여
3.
→ MySQL DB의 도서의 Status가 POSSIBLE→IMPOSSIBLE로 변경(Ajax요청→MySQL DB)
4.
→ Logstash가 modified_at을 감지(Logstash의 1분 주기)
5.
→ 해당 row를 Elasticsearch에 전달하여 맞춤
6.
→ Elasticsearch로부터 도서의 변경된 정보가 뷰페이지에 반영됨
위 과정에서 3번과 4번의 시간차이가 발생합니다.
3번은 HTML 버튼의 Ajax요청에 따라 MySQL의 데이터를 동적으로 거의 즉시 변경하게 되는데
4번의 과정은 1분이라는 주기를 통해 변경된 점을 확인한 이후에 Elasticsearch의 인덱스에 전달하게 되므로 최대 1분의 뷰 페이지가 그대로 POSSIBLE로 유지될 가능성이 있습니다.
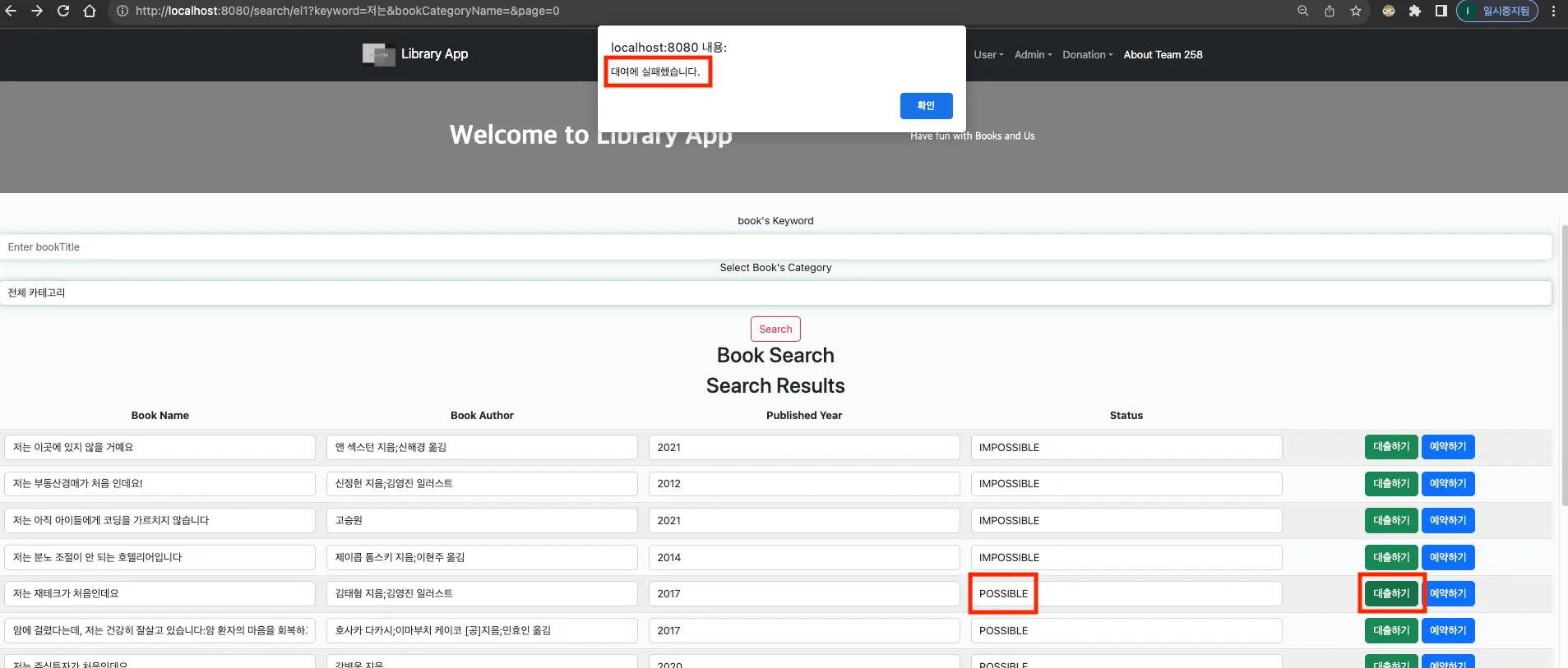
물론 MySQL의 데이터 자체가 이미 IMPOSSIBLE로 변경된 상태기 때문에 방금 대여된 도서를 대여하고자 접근 할 수는 없지만, 사용자 편의상 POSSIBLE 상태로 잘못된 정보가 오래 노출되는것은 웹서비스의 신뢰도를 낮추는 좋지 않은 상황으로 판단되었습니다.
Logstash를 통한 동기화 시간차이의 현황
이에 따라 위 동기화 시간을 최소화 시키고자 schedule => "*/1 * * * * *" 처럼 cron 표현식을 1초단위로 수정하고 실행해보았습니다.
# sample.conf
# 초기 데이터 색인을 위한 input/output 블록
input {
jdbc {
jdbc_connection_string => "jdbc:mysql://localhost:3306/team258"
jdbc_user => "inyongkim"
jdbc_password => "1234"
jdbc_driver_library => "/Users/inyongkim/.gradle/caches/modules-2/files-2.1/mysql/mysql-connector-java/8.0.25/f8b9123acd13058c941aff25f308c9ed8000bb73/mysql-connector-java-8.0.25.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_paging_enabled => true
jdbc_page_size => 50000 # JVM 메모리 부하 감당할 수 있는 정도로 설정
# schedule => "* * * * *" # 서버실행시 1회만 실행되도록 주기 제거
statement => "SELECT * FROM book"
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "book"
document_id => "%{book_id}"
}
}
# 주기적인 업데이트를 위한 input/output 블록 -> 즉시 업데이트로 변경
input {
jdbc {
jdbc_connection_string => "jdbc:mysql://localhost:3306/team258"
jdbc_user => "inyongkim"
jdbc_password => "1234"
jdbc_driver_library => "/Users/inyongkim/.gradle/caches/modules-2/files-2.1/mysql/mysql-connector-java/8.0.25/f8b9123acd13058c941aff25f308c9ed8000bb73/mysql-connector-java-8.0.25.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
# schedule => "* * * * * *" # 기본 1분
schedule => "*/1 * * * * *" # 1초
last_run_metadata_path => "/Users/inyongkim/Documents/logstashtmp/last_run_metadata_file"
statement => "SELECT * FROM book WHERE modified_at > :sql_last_value"
use_column_value => true
tracking_column => "modified_at"
tracking_column_type => "timestamp"
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "book"
document_id => "%{book_id}"
action => "update"
doc_as_upsert => true
}
}
Java
복사
주기는 1초로 설정했지만 실제 modified_at의 변경사항을 추적하는데 소요되는 시간은 평균 7초 이상을 기록하고 있습니다. 각 실행이 완료되는 데 약 7.65초 소요되고 있습니다. 따라서 1초 주기로 실행되고 있는데도 실행 간격이 충분히 짧아 보이지 않는 것은 각 실행이 중첩되고 있기 때문입니다.
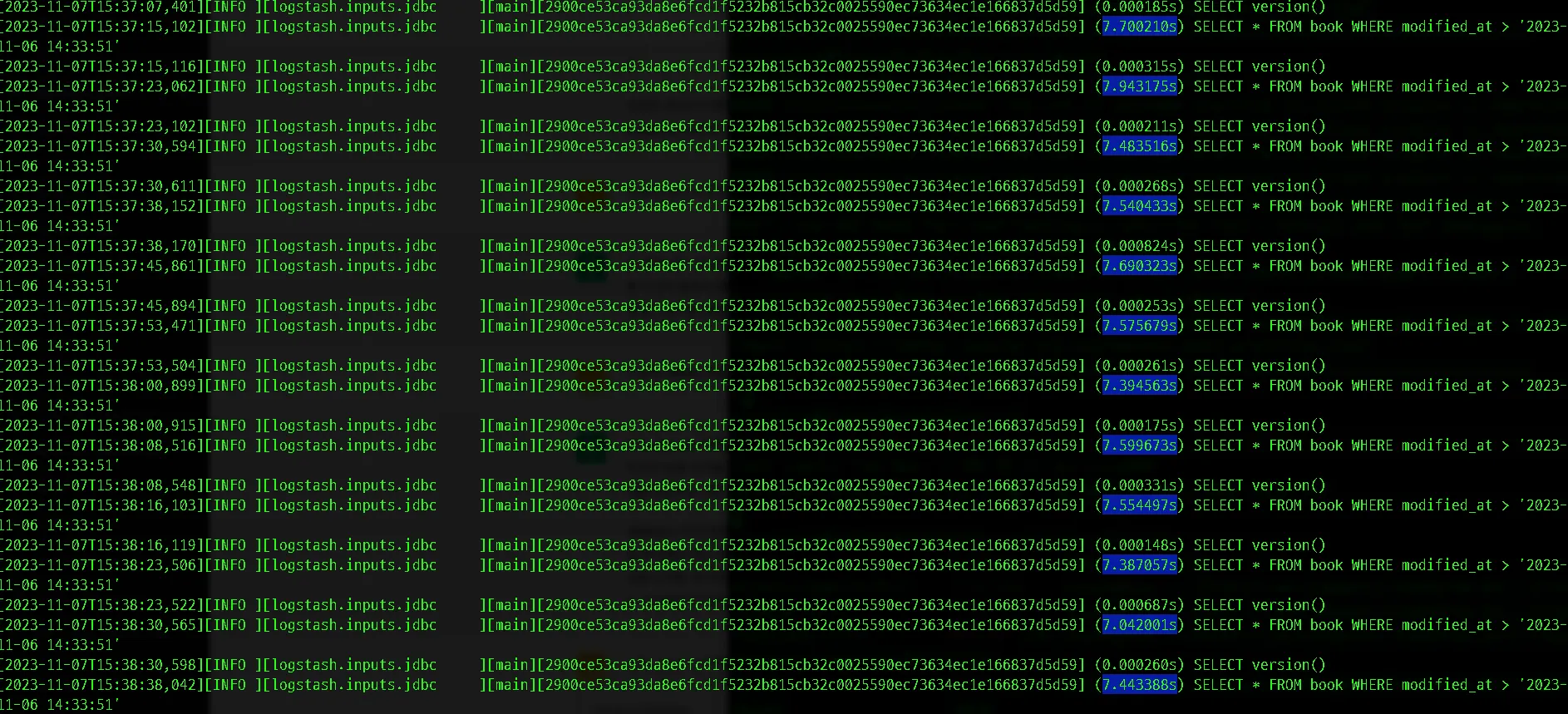
주기를 넉넉하게 5초로 설정했지만 평균 7.xx초를 소요하면서 역시나 절대적인 실행 시간에 영향을 주지 못하는 것을 확인 할 수 있었습니다.
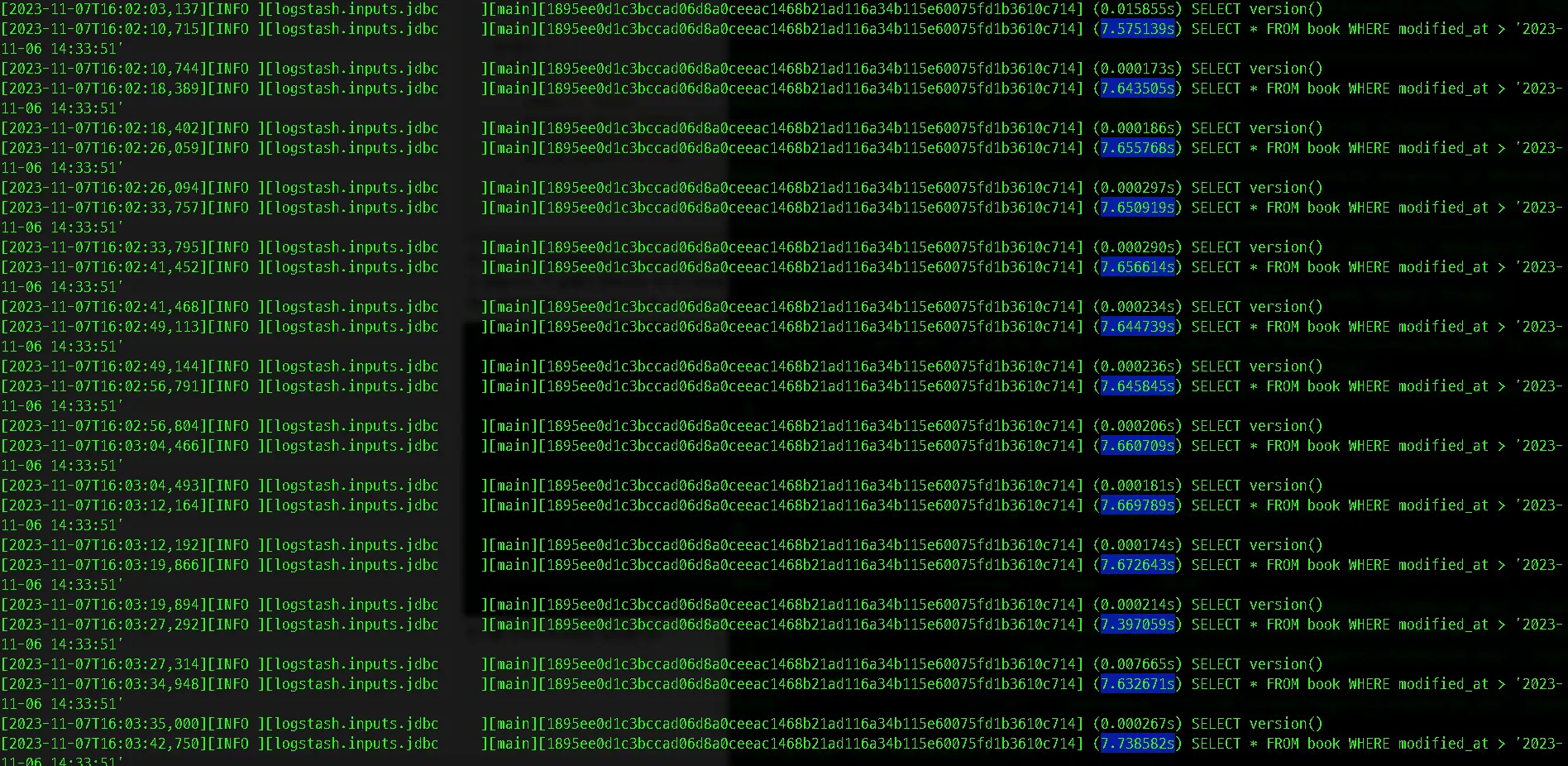
ElasticSearch와의 효율적인 통신을 위해서는 적절한 주기를 찾는 것이 중요하지만, 너무 잦은 주기로 업데이트를 실행하는 것은 너무 자주 요청을 보내게 될 수 있으므로 비용이 증가 하게 됩니다.
실시간 연동을 위한 방안 생각
실시간 반영이 필요하다면, Logstash와 ElasticSearch 외에도 다른 방법을 고려할 필요가 있었습니다.
직접 HTTP 요청을 통해 MySQL과 Elasticsearch로 동시에 호출하는 것은 빠르고 직접적인 방법 중 하나일 수 있습니다. 이를 통해 Logstash의 스케줄링 및 처리 지연과 같은 요소들을 우회할 수 있습니다.
MySQL에서 트리거를 설정하여 데이터가 변경될 때마다 Elasticsearch에 직접 HTTP 요청을 보내는 방법은 상대적으로 간단하지만, 데이터의 일관성과 정확성을 보장하기 위해 조심스럽게 구현해야 합니다. 변경 이벤트를 캡처하고 적절한 형식으로 Elasticsearch로 전송하는 것이 주된 목표이기 때문에, 이에 대한 로직을 신중하게 구현해야 합니다.
데이터의 일관성과 정확성을 보장하는 것 중요하다.
락을잡고 하는것
or 카프카를 활용
실시간 연동을 위해 테스트해볼만한 추가 방안
MySQL에서 직접 트리거를 사용하거나, 변경 로그를 캡처하는 CDC(Change Data Capture) 도구를 사용할 수 있다는 방안을 생각하게 되었습니다.
이런 방법들은 데이터베이스의 변경을 실시간으로 감지하고, 이벤트를 트리거하여 ElasticSearch로 전송하는 방식으로 MySQL과 Elasticsearch와의 빠른 동기화를 유지 할 것으로 판단되었습니다.
트리거를 사용
CDC(Change Data Capture) 도구를 사용(추후구현필요) →