

Kafka를 시도하는 이유
1.
현재 진행 중인 프로젝트의 서비스는 대용량 트래픽을 받는 서비스입니다.
→ kafka를 사용하면 데이터 베이스나 애플리케이션에 락을 걸지 않고 전송 속도를 제어해서 동시성 문제가 발생하지 않는 속도로 순차적으로 전달한다면 락보다 속도가 빠를것입니다.
2.
확장성이 중요한 경우
→ 서비스가 계속 성장하고 더 많은 트래픽을 처리해야 할 경우, Kafka는 쉽게 확장할 수 있는 구조를 가지고 있어 미래의 성장에 대비할 수 있습니다.
3.
탄력성과 고가용성이 중요한 경우
→ Kafka는 분산 시스템으로 설계되어 있어 노드 하나가 실패하더라도 서비스의 가용성을 유지할 수 있습니다.
즉 저희 서비스의 확장성과 안정성, 서버 과부하 방지, 동시성 문제를 성능 저하하는 락없이 해결하기 위해 카프카를 시도하였습니다.
KafKa의 동작 흐름
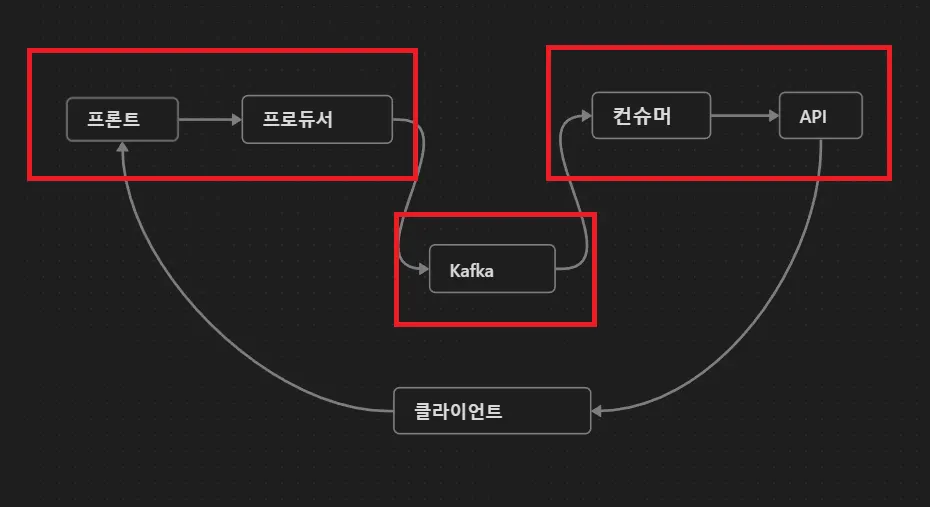
1.
프론트엔드에서 요청: 사용자의 액션에 의해 프론트엔드에서 백엔드로 HTTP 요청이 전송됩니다.
2.
Kafka 컨트롤러: Spring Boot 어플리케이션 내의 컨트롤러가 HTTP 요청을 받아 처리합니다.
3.
Kafka 프로듀서: 컨트롤러는 Kafka 프로듀서를 통해 메시지를 Kafka 서버의 특정 토픽으로 전송합니다.
4.
Kafka 서버: Kafka 클러스터는 메시지를 받아 토픽에 저장하고, 이 메시지를 구독하고 있는 컨슈머에게 전달합니다.
5.
Kafka 컨슈머: Kafka 컨슈머는 메시지를 받아 필요한 비즈니스 로직을 처리합니다. 이 과정에서 외부 API를 호출할 수도 있습니다.
6.
API 호출 (선택적): 필요한 경우 컨슈머는 외부 API를 호출하여 추가적인 처리를 진행합니다.
Kafka를 이용한 동시성 문제 구조적 해결 및 한계
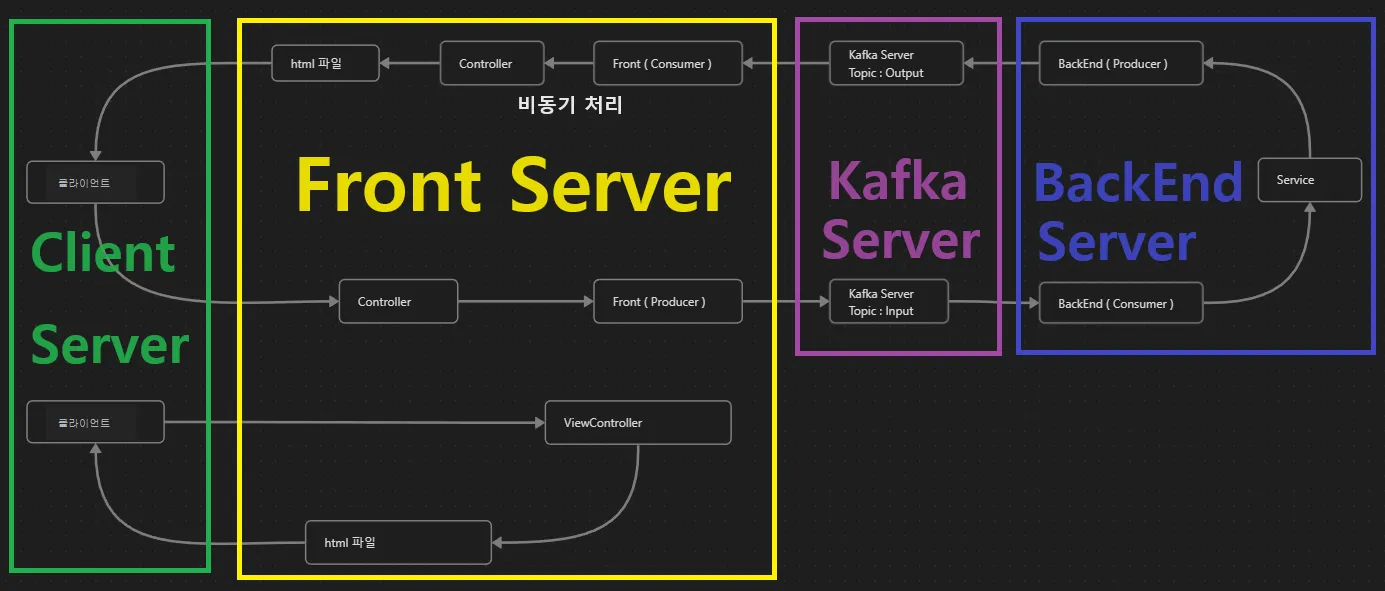
Kafka를 도입할 때 Kafka의 구조와 특성으로 동시성 문제를 자연스럽게 해결할 수 있을 것이라 기대하였습니다.
Kafka는 메시지를 파티션 단위로 관리하며, 각 파티션은 순서를 가진 로그로 구성되어 있습니다.
따라서 단일 파티션, 단일 서버의 상황에 대해서는 프로듀서와 컨슈머 간의 동시성 문제를 구조적인 해결이 가능했습니다.
그러나 서비스가 확장됨에 따라 발생하는 여러 파티션과 서버들의 복잡한 상황에서는 이 같은 동시성 문제가 여전히 존재한다는 것을 인식하게 되었습니다. 특히 단일 파티션에 의존하는 상황에서는 카프카의 병렬 처리 장점을 충분히 활용하지 못하며, 이는 또한 마이크로서비스 아키텍처의 유연한 확장성에도 제한을 가져옵니다.
이에 따라, 카프카만으로는 동시성 문제를 해결하는 데 한계가 있다는 결론에 도달했고, 이를 보완할 추가적인 방안을 모색하게 되었습니다. 분산 락을 도입하여 각 컨슈머가 리소스에 독립적으로 접근하게 함으로써, 동시성 문제를 더욱 효과적으로 관리할 수 있을 것으로 보고 있습니다. Redis와 같은 분산 락 시스템을 통해 동시에 하나의 컨슈머만이 리소스에 접근하도록 조정하여, 카프카 시스템 내에서 발생할 수 있는 동시성 문제를 완화시킬 계획입니다.
여러 컨슈머가 동일한 리소스에 접근해야 하는 상황에서 Redis를 사용하여 분산 락을 구현함으로써, 한 번에 하나의 컨슈머만이 리소스에 접근할 수 있도록 제어하는 방향으로 말입니다.
결국 카프카의 분산 처리 능력과 분산 락 시스템을 결합함으로써, 데이터베이스 락이 내포하는 데드락 위험을 줄이고, 확장성과 유연성을 손상시키지 않으면서 동시성 문제를 해결해 나가려고 합니다.