

더보기 기능의 구현 모습

불편함으로 부터 시작
웹 서비스에서 페이징은 아주 흔하게 사용되는 기능입니다. 다만, 기초적인 페이징 구현 방식은 서비스가 커짐에 따라 큰 장애를 유발할 수 있는데요.
서비스 초기에는 수천 ~ 수십만건정도로 데이터가 적어서 큰 문제가 없지만, 점차 적재된 데이터가 많아짐에 따라 페이징 기능이 수십초 ~ 수분까지 조회가 느려지는걸 경험하게 됩니다.
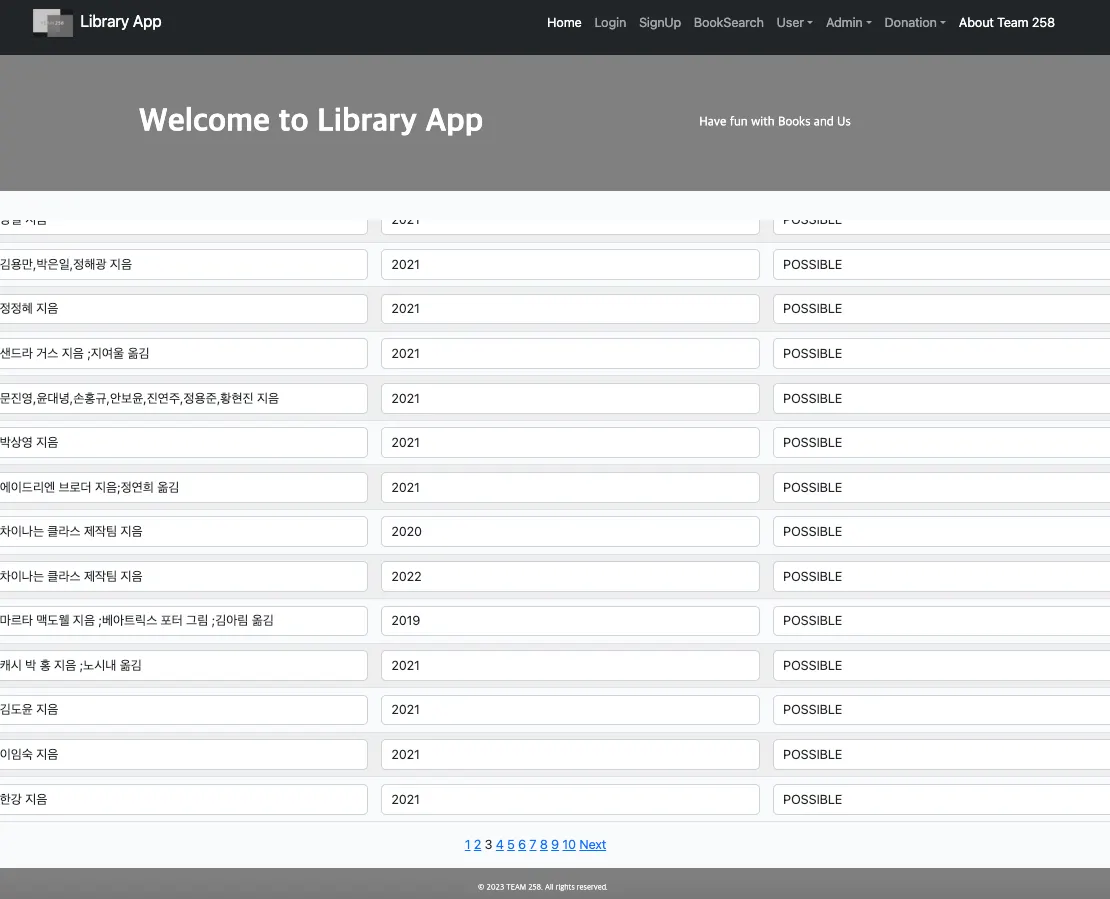
실제로 도서 목록이 나타나는 저희 프로젝트에서도 기본적인 페이징을 구현했었습니다. 하지만 각 페이지를 이동 할 때마다 약 1.0~1.2초가 소요될 정도로 “느리다”, “원활하지 않다” 라는 점을 직접 체감 할 수 있었습니다.
페이징의 문제점을 해결하기 위해 더보기 기능으로 비교
기존의 페이징 방식은 페이지 번호 (offset) 와 페이지 사이즈 (limit) 를 기반으로 한다면,
No Offset은 아래와 같이 페이지 번호 (offset)가 없는 더보기 (More) 방식을 이야기 합니다.
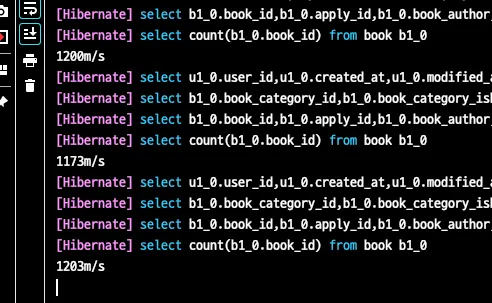
단순히 두개의 첫 페이지 진입 속도 차이를 보면 페이징 방식은 1,234m/s인 반면 더보기 방식은 5m/s인것으로 나타나고 있습니다.
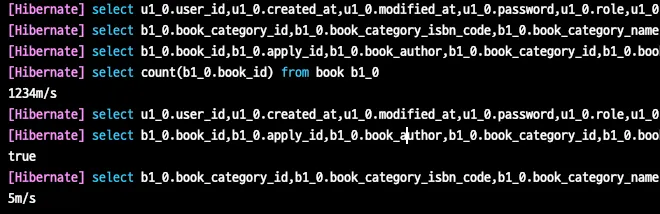
두번째 페이지 진입 속도를 보면 페이징 방식은 전체 페이지를 산정해야하는 전체 책을 조회하는 count문으로 부터 상당한 시간이 걸리기 때문에 고정적으로 1200m/s 정도로 비교적 좋지 않은 성능을 일관적으로 유지하고있습니다.
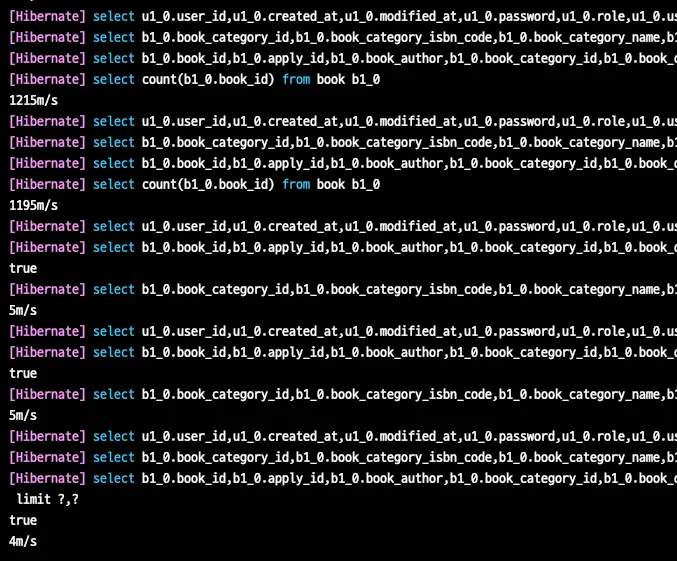
여기서 저희 프로젝트의 페이징 방식에서 offset 쿼리가 보이지 않는 것은 전체 데이터를 가져와서 일부만 보여주는 방식이 필요했기 때문입니다. 전체 도서의 페이징에서 offset을 사용하지 않고 LIMIT만 사용하면서 전체 데이터에 대한 목록을 보여주는 것이 목적에 맞다고 판단했습니다.
반례로 offset을 100으로 설정한다면 수만개의 도서 데이터가 있더라도 100페이지만큼의 데이터 이외의 데이터는 없는것으로 처리하기 때문에 모든 데이터를 볼 수 있도록 하는 것을 위해 사용하지 않게 되었습니다.
만약 offset을 사용하더라도 문제가 발생합니다. 예를 들어 offset 10000, limit 20 이라 하면 최종적으로 10,020개의 행을 읽어야 합니다. (10,000부터 20개를 읽어야하니) 그리고 이 중 앞의 10,000 개 행을 버리게 됩니다. (실제 필요한건 마지막 20개뿐이니) 따라서 뒤로 갈수록 버리지만 읽어야 할 행의 개수가 많아 점점 뒤로 갈수록 느려지는 것입니다.

하지만 더보기(슬라이스 구현체)로는 불필요한 전체 도서 데이터의 갯수를 산정하지 않습니다. 단순히 다음 페이지의 데이터가 있는가 없는가에 대한것을 체크하고 쿼리 자체는 다음과 같이 작동합니다.
[Hibernate]
select
b1_0.book_id,b1_0.apply_id,b1_0.book_author,b1_0.book_category_id,
b1_0.book_donation_event_id,b1_0.book_name,b1_0.book_publish,
b1_0.rent_id,b1_0.book_status
from
book b1_0
where
b1_0.book_name like ? escape '!'
order by
b1_0.book_id limit ?,?
Java
복사
이 쿼리에서 ORDER BY b1_0.book_id는 book_id를 기준으로 정렬하고,
중요한 부분은 페이징의 방식을 나타내는 LIMIT ?, ?부분으로 입니다.
첫 번째 ?는 시작 인덱스(건너뛸 행 수)이고, 두 번째 ?는 가져올 행의 수입니다.
이렇게 구성된 쿼리는 특정 조건(book_name의 부분 일치)으로 필터링되고, book_id를 기준으로 정렬된 후에 OFFSET 없이 LIMIT을 통해 페이징이 구현됩니다. 이 방식은 "No Offset" 방식이라고도 불립니다. 따라서 가져올 행의 수가 20으로 고정되어서 아무리 페이지가 뒤로 가더라도 처음 페이지를 읽은 것과 동일한 성능을 가지게 됩니다.
[구현 코드] JavaScript의 HTTP 요청 구현부
더보기 버튼을 누르면, DispatcherServlet 을 거쳐 /search/loadMore 라는 API 엔드포인트로 다음 페이지의 데이터를 요청합니다.
// 모듈화된 JS
let currentPage = 0;
// 페이지 로딩 시
$(document).ready(function() {
window.goToNextPage = function() {
// 서버에 다음 페이지 데이터 요청
$.ajax({
type: 'GET',
url: '/search/loadMore', // 엔드포인트 변경
data: {
bookCategoryName: $('#bookCategoryId').val(),
keyword: $('#keyword').val(),
page: currentPage + 1 // 다음 페이지로 이동
},
dataType: 'json', // 추가
success: function(data) {
console.log(data);
// books 배열에 접근하도록 수정
data[0].bookResponseDtos.forEach(book => {
let bookHtml = `<tr>
<td><input class="form-control" type="text" value="${book.bookName}" name="userId" readonly/></td>
<td><input class="form-control" type="text" value="${book.bookAuthor}" name="username" readonly/></td>
<td><input class="form-control" type="text" value="${book.bookPublish}" name="role" readonly/></td>
<td><input class="form-control" type="text" value="${book.bookStatus}" name="role" readonly/></td>
<td>
<button type="button" class="btn btn-success rent-button" data-book-id="${book.bookId}">대출하기</button>
<button type="button" class="btn btn-primary reserve-button" data-book-id="${book.bookId}">예약하기</button>
</td>
</tr>`;
// 동적으로 생성된 HTML을 현재 테이블에 추가
$('#load-more-test').append(bookHtml);
});
// 현재 페이지 업데이트
currentPageThymeleaf++;
// 서버에서 받은 다음 페이지 값으로 업데이트
currentPage = currentPageThymeleaf;
},
error: function(xhr, status, error) {
// 오류 처리 로직
console.error(error);
}
});
}
});
JavaScript
복사
[구현 코드] Controller
DispatcherServlet가 HTTP 요청을 해석하고 그에 맞는 컨트롤러로 분배 하면 요청을 받아내는 컨트롤러 부분입니다. /search/loadMore 라는 API 엔드포인트에서 HTTP 요청에 담긴 값들을 매개변수로 받고 있습니다. 그 중 page라는 쿼리스트링은 더보기 버튼을 누를때 마다 JavaScript에서 계속해서 1씩 증가하며 다음페이지를 요청하도록 구현되어 있었습니다.
주요 특징은 Slice 인터페이스를 사용하고 있는 점으로 특징은 다음과 같습니다.
•
컨텐츠를 가져오는데 필요한 최소한의 메타데이터만 포함합니다. (getContent(), hasNext(), hasPrevious(), getNumber(), getSize() 등)
•
전체 페이지 카운트를 알 필요가 없을 때 사용됩니다.
•
다음 페이지가 있는지 여부를 판단하기 위해 hasNext() 메서드를 사용할 수 있습니다.
반면, 이전에 사용했던 Page 인터페이스의 특징은 다음과 같습니다.
•
Page는 Slice보다 더 많은 페이징 정보를 제공하는 인터페이스입니다.
•
전체 페이지 수, 전체 항목 수 등의 메타데이터를 제공합니다.
•
getContent(), getTotalElements(), getTotalPages(), getNumber(), getSize() 등의 메서드가 있습니다.
•
전체 페이지 수 및 전체 항목 수를 알아야 하는 경우에 유용합니다.
@Controller
@RequiredArgsConstructor
public class SearchMixedController {
private final SearchService searchService;
private final AdminCategoriesService adminCategoriesService;
...
// 더보기 기능 구현 추가 페이지 로드
@GetMapping("/search/loadMore")
@ResponseBody
public ResponseEntity<List<BookResponseLoadMoreDto>> loadMoreResults(
@RequestParam(value = "bookCategoryName", required = false) String bookCategoryName,
@RequestParam(value = "keyword", required = false) String keyword,
@RequestParam(value = "page", defaultValue = "0", required = false) Integer page) {
long startTime = System.currentTimeMillis();
Slice<BookResponseDto> bookResponseDtoLoadMore = searchService.getMoreBooksByCategoryOrKeyword(bookCategoryName, keyword, page);
long endTime = System.currentTimeMillis();
long durationTimeSec = endTime - startTime;
System.out.println(durationTimeSec + "m/s");
List<BookResponseLoadMoreDto> responseList = Collections.singletonList(
new BookResponseLoadMoreDto(bookResponseDtoLoadMore.getContent())
);
return ResponseEntity.ok(responseList);
}
...
}
Java
복사
[구현 코드] Service
서비스 계층의 비지니스 로직입니다. QueryDSL을 사용하고 있으며 이에 따라 Builder를 통해 기존 서비스의 조건 기능과 같은 키워드 검색, 태그 검색 등이 처리되고 있습니다.
builder에 쿼리의 조건들, pageable에 페이징을 위한 조건들이 객체로 담겨지고 customBookRepository에 구현된 findAllSliceBooks 구현체에 인자(Arguments)로 전달됩니다.
추후 이를 통해 반환된 데이터들은 추후 List로 정리되고 List를 Dto에 담아 반환되게 됩니다.
@Service
@RequiredArgsConstructor
public class SearchService {
private final BookRepository bookRepository;
private final BookCategoryRepository bookCategoryRepository;
private final CustomBookRepository customBookRepository;
...
//더보기용 서비스
public Slice<BookResponseDto> getMoreBooksByCategoryOrKeyword(String bookCategoryName, String keyword, int page) {
QBook qBook = QBook.book;
BooleanBuilder builder = new BooleanBuilder();
List<BookCategory> bookCategories = new ArrayList<>(); // 초기화
if (bookCategoryName != null) {
BookCategory bookCategory = bookCategoryRepository.findByBookCategoryName(bookCategoryName);
if (bookCategory != null) { // null 체크 추가
bookCategories = saveAllCategories(bookCategory);
}
}
if (keyword != null)
builder.and(qBook.bookName.contains(keyword));
if (!bookCategories.isEmpty()) // 리스트가 비어있는지 확인
builder.and(qBook.bookCategory.in(bookCategories));
Sort sort = Sort.by(Sort.Direction.ASC, "bookId");
Pageable pageable = PageRequest.of(page, 20, sort);
// Slice로 추가 로드 데이터 가져오기
Slice<BookResponseDto> bookList = customBookRepository.findAllSliceBooks(builder, pageable).map(BookResponseDto::new);
System.out.println(bookList.hasNext());
return bookList;
}
...
}
Java
복사
[구현 코드] Repository
추상화된 Repository는 다음과 같습니다.
@Repository
public interface CustomBookRepository {
Slice<Book> findAllSliceBooks(BooleanBuilder builder, Pageable pageable);
}
Java
복사
추상 클래스의 실제 구현체 CustomBookRepositoryImpl은 레포지토리 계층에서는 실제로 데이터를 조회하는 역할을 하게 됩니다. 그 역할은 QueryDSL의 클래스인 JPAQueryFactory가 실행합니다. 클래스에서 제공되는 selectFrom(), where()과 같은 메서드를 통해서 쿼리문을 Java 메소드를 사용하는것 처럼 사용 할 수 있도록 하여 컴파일 단계에서도 오류를 찾아 낼 수 있는 도움을 줍니다.
@Repository
public class CustomBookRepositoryImpl implements CustomBookRepository{
@Autowired
private JPAQueryFactory queryFactory;
@Override
public Slice<Book> findAllSliceBooks(BooleanBuilder builder, Pageable pageable) {
QBook book = QBook.book;
List<Book> results = queryFactory.selectFrom(book)
.where(builder)
.limit(pageable.getPageSize()+1)
.orderBy(book.bookId.asc())
.offset(pageable.getOffset())
.fetch();
boolean hasNext = false;
if(results.size() > pageable.getPageSize()){
results.remove(results.size()-1);
hasNext = true;
}
return new SliceImpl<>(results,pageable,hasNext);
}
}
Java
복사
[구현 코드] 브라우저까지의 응답과 마지막 HTML의 표현
위 Controller→Service→Repository→DB 까지의 데이터 흐름 이후 반환된 모든 데이터들은 역순으로 서버 내 최초 호출 위치인 Controller 까지 전달될 것이며, 그 Controller는 DispatcherServlet 에 응답을 전달합니다. DispatcherServlet 은 최초 요청 시작점인 JavaScript로 응답을 보내게 됩니다.
응답 데이터는 클라이언트에 JSON 형태로 도착하고 JavaScript의 Success 함수에 따라 HTML에 각 행(row)별로 테이블이 목록화되어 누적되게 됩니다.

아래 HTML 구조는 복잡해보이지만, Thymeleaf 엔진을 통해 부분적 레이아웃 블록들을 소환하는 방식을 사용하고 있습니다. 응답받은 위 데이터는 JavaScript에 의해 Key-Value에 맞는 태그를 찾아 값들이 임시 HTML에 들어가게 되며 <tbody id="load-more-test"> 라는 지정해 둔 위치에 동적으로 다음 페이지 도서들이 브라우저에 추가되는 모습을 볼 수 있습니다
<!DOCTYPE html>
<html lang="en" xmlns:th="http://www.thymeleaf.org">
<!-- 헤드 레이아웃 적용 -->
<head th:insert="~{layout :: head}"></head>
<head>
<!-- 나의 도서 대여 및 예약 관련 -->
<script src="https://code.jquery.com/jquery-3.6.0.min.js"></script>
<script src="/js/users/bookSearchLM1.js"></script>
</head>
<body>
<div th:replace="~{layout :: nav}"></div>
<!-- 헤더 레이아웃 적용 -->
<div th:replace="~{layout :: header}"></div>
<div class="index-contents">
<!-- 컨텐츠(여기부터 삽입 됩니다.) -->
...
<div class="mb-3">
<label class="form-label" for="keyword">book's Keyword</label>
<input class="form-control" type="text" placeholder="Enter bookTitle" name="keyword" id="keyword"/>
...
<table class="table table-striped">
<thead>
<tr>
<th>Book Name</th>
<th>Book Author</th>
<th>Published Year</th>
<th>Status</th>
</tr>
</thead>
<tbody>
<tr th:each="book : ${books}">
<td><input class="form-control" type="text" th:value="${book.bookName}" name="userId" readonly/></td>
...
</tbody>
<tbody id="load-more-test">
<!-- 더보기로 로드된 항목이 이곳에 추가됩니다. -->
</tbody>
</table>
<!-- Add more rows here -->
<!-- Pagination links -->
<div id="paging">
<button id="load-more-button" th:if="${hasNext}" onclick="goToNextPage()">더보기</button>
</div>
<!-- 컨텐츠(여기까지 삽입 됩니다.) -->
</div>
<!-- 푸터 레이아웃 적용 -->
<div th:replace="~{layout :: footer}"></div>
<!-- 페이지 번호를 저장하는 input -->
<script th:inline="javascript">
/*<![CDATA[*/
let currentPageThymeleaf = [[${currentPage}]];
/*]]>*/
</script>
</body>
</html>
Java
복사