로컬(나의 컴퓨터)의 외부접속 환경 만들어서 테스트하기
MySQL의 도서데이터는 book 테이블에 존재하고 709만 개의 대용량데이터로 이동 성공 및 실패를 떠나 AWS에 큰 비용을 초래할 수 있기 때문에 충분한 테스트를 진행하고 있는 과정입니다. 따라서 비교적 데이터양이 적은 book_category로 테스트를 우선 진행하고자 합니다.
Elasticsearch, Logstash, Kibana는 다른 컴퓨터(EC2 인스턴스)에 있으며 특히 Logstash는 내 컴퓨터의 MySQL에 접근해야 합니다. 따라서 내 컴퓨터의 MySQL의 외부 접속을 가능하도록 해야 합니다.
이는 AWS RDS에 MySQL을 구축해둔 프로젝트의 방향과 비슷하게 localhost가 아닌 특정 주소를 통해서 데이터를 받아 올 수 있는지에 대한 원격 접근을 테스트하기 위함입니다.
나의 로컬 컴퓨터의 콘솔에서 MySQL의 설정 파일을 찾아야 합니다. 우선 my.cnf 또는 my.ini라는 파일을 찾아야 합니다. 저의 경우 Homebrew를 통해 MySQL을 설치 했기 때문에 /usr/local/etc/ 라는 경로에서 찾을 수 있습니다.

해당 파일을 vi 에디터를 통해 열어보면 MySQL server 설정 정보가 나타나있습니다. 기본 설정은 localhost로 작동하도록 되어 있습니다.
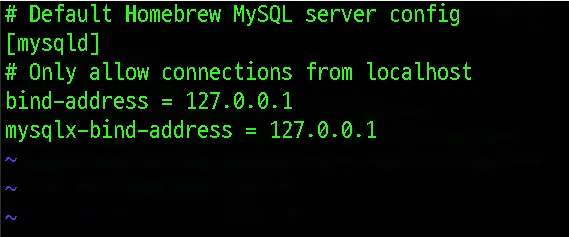
bind-address = 127.0.0.1 부분을 bind-address = 0.0.0.0으로 변경해줍니다.
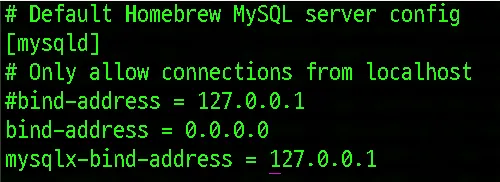
이제 mysql 서버를 재시작해줍니다.
brew services restart mysql
Shell
복사
현재 계정들은 localhost에 대한 접근 권한을 가진 유저들밖에 없습니다.
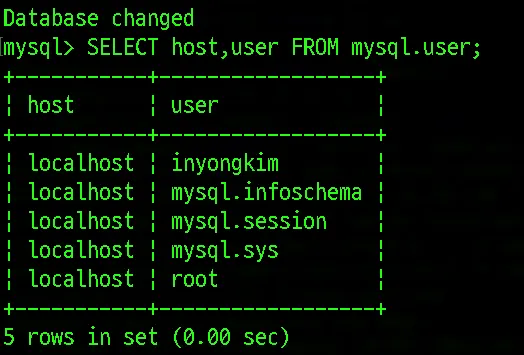
root으로 MySQL에 접속해서 %로 표기된 모든 호스트로부터 접근 권한을 가진 유저를 만들어봅니다.
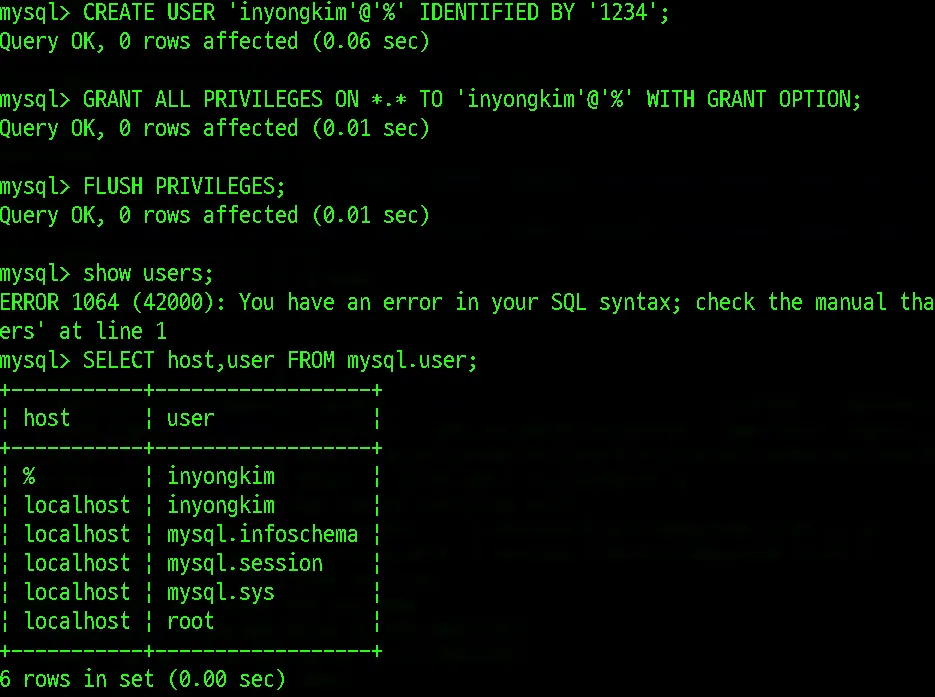
이제 해당 로컬 컴퓨터(Mac)의 외부IP(인터넷과 연결된 실제 IP)로 MySQL에 접근 할 수 있을 줄 알았지만, 응답이 없는 문제가 발생했었습니다. 이는 외부 IP의 포트가 다른 내부 네트워크 설정의 타 프로젝트와 연결되어 충돌이 나타나는 부분이 있었고 mysql의 포트를 내부 포트와 외부포트를 연결하여 외부IP:3306으로 접근 가능하도록 포트포워딩을 진행했습니다.
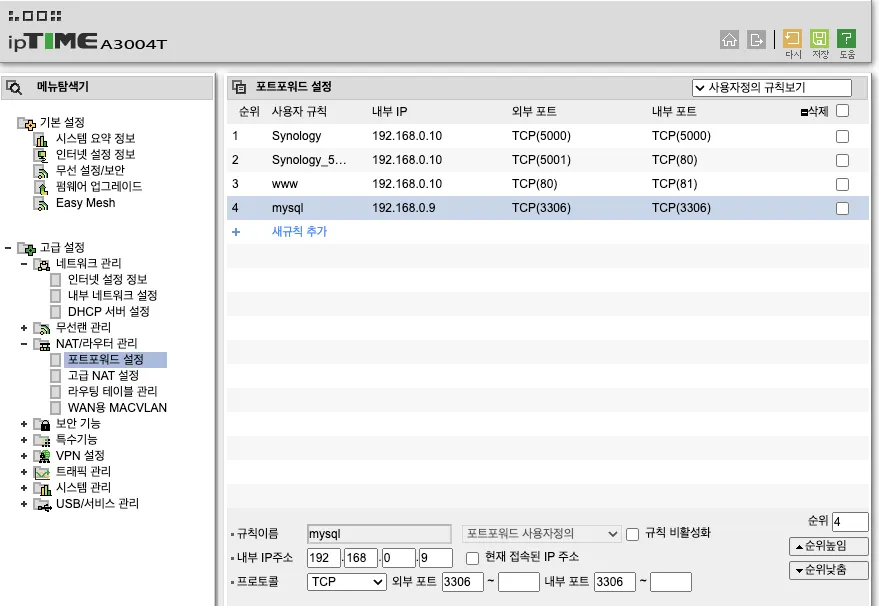
이후 localhost가 아닌 IP주소를 통한 외부 접속이 가능하게 되었습니다.
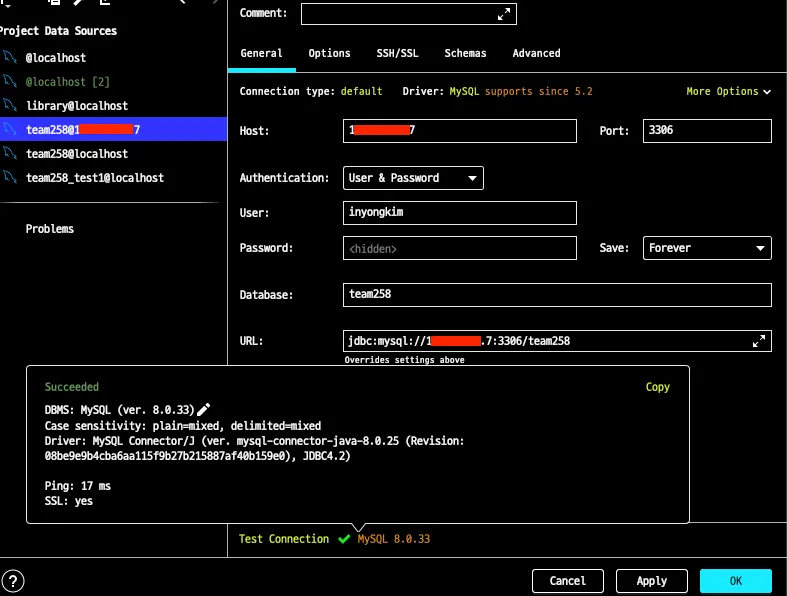
실제로 다른 위치에 있는 컴퓨터인 EC2에서도 해당 IP:PORT로 접속을 시도했으며,

접속에 성공하는 모습을 확인 할 수 있었습니다.
Logstash를 통한 타 서버(로컬PC)의 데이터를 EC2에 설치된 Elasticsearch에 전달
Logstash를 통해 다른 인스턴스로 구분된 MySQL과 Elasticsearch간의 데이터를 전달하고자 합니다.
Logstash는 MySQL과의 연결을 위해서 jdbc_driver가 필요하며, EC2내부에 설치하여 MySQL의 커넥션 정보를 제공해주어야 합니다.
RDS라고 가정한 외부 접속 MySQL에서부터 EC2로 Logstash를 통한 데이터 전달
우선 로컬에서 비교적 적은 데이터의 이동부터 테스트를해서 외부접속 IP로 구성된 MySQL로부터 Logstash로 데이터가 전달되는지 확인해보고자합니다.
Logstash의 input/output 를 정의하는 사용자 설정 파일인 sampletest1.conf을 만들어보았습니다.
# sampletest1.conf
# 초기 데이터 색인을 위한 input/output 블록
input {
jdbc {
jdbc_connection_string => "jdbc:mysql://{외부IP주소}:3306/team258"
jdbc_user => "inyongkim"
jdbc_password => "1234"
jdbc_driver_library => "/Users/inyongkim/.gradle/caches/modules-2/files-2.1/mysql/mysql-connector-java/8.0.25/f8b9123acd13058c941aff25f308c9ed8000bb73/mysql-connector-java-8.0.25.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
# jdbc_paging_enabled => true
# jdbc_page_size => 50000 # JVM 메모리 부하 감당할 수 있는 정도로 설정
# schedule => "* * * * *" # 서버실행시 1회만 실행되도록 주기 제거
statement => "SELECT * FROM book_category"
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "book_category"
document_id => "%{book_category_id}"
}
}
Shell
복사
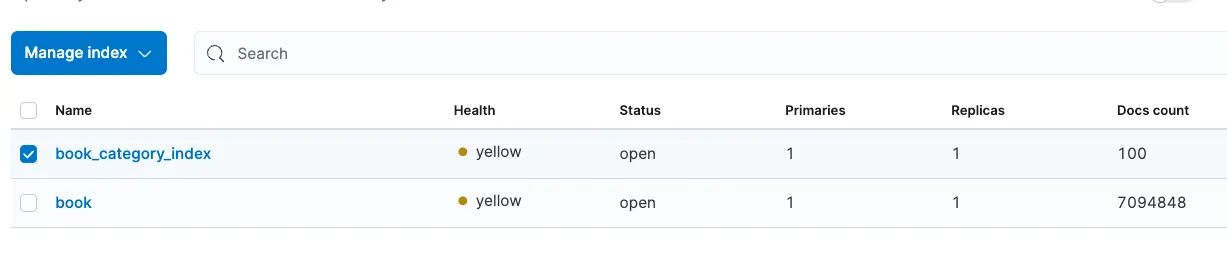
기존 Local To Local 테스트 데이터가 남아있어서 book_category_index 인덱스를 삭제하여 카테고리 관련 테이블이 없도록 하였습니다.

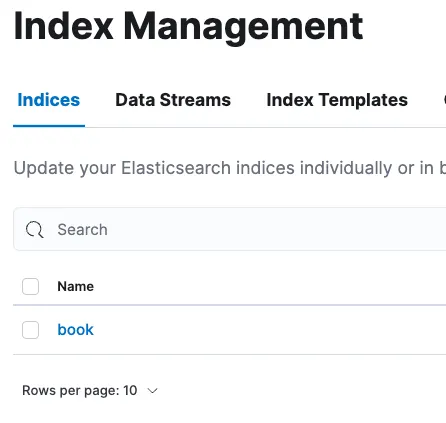
이제 직접 생성한 logstash의 .conf 파일을 실행시켜 book_category 인덱스를 Elasticsearch에 전달하도록 합니다. 주요 변경점은 MySQL 데이터의 출처가 로컬이었던 점에서 외부접속을 활용한 것으로 프로젝트가 RDS로 MySQL이 별도로 구성되어 있는 경우에도 해당 주소로 MySQL을 접근하여 데이터를 가져오는지 확인하는 것과 같습니다.
/usr/local/bin/logstash -f /usr/local/etc/logstash/sampletest1.conf
Shell
복사
다음과 같이 해당 설정 파일의 input/output 블록이 모두 정상적으로 실행되었으며,
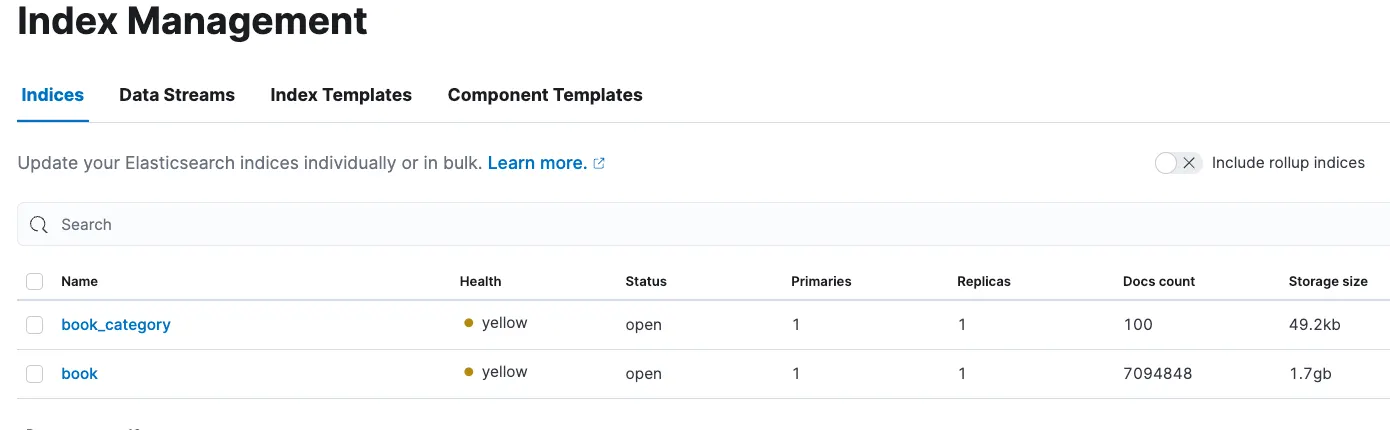
book_category라는 인덱스(테이블)이 생성되었고, 100개의 데이터를 정상적으로 가져왔습니다.
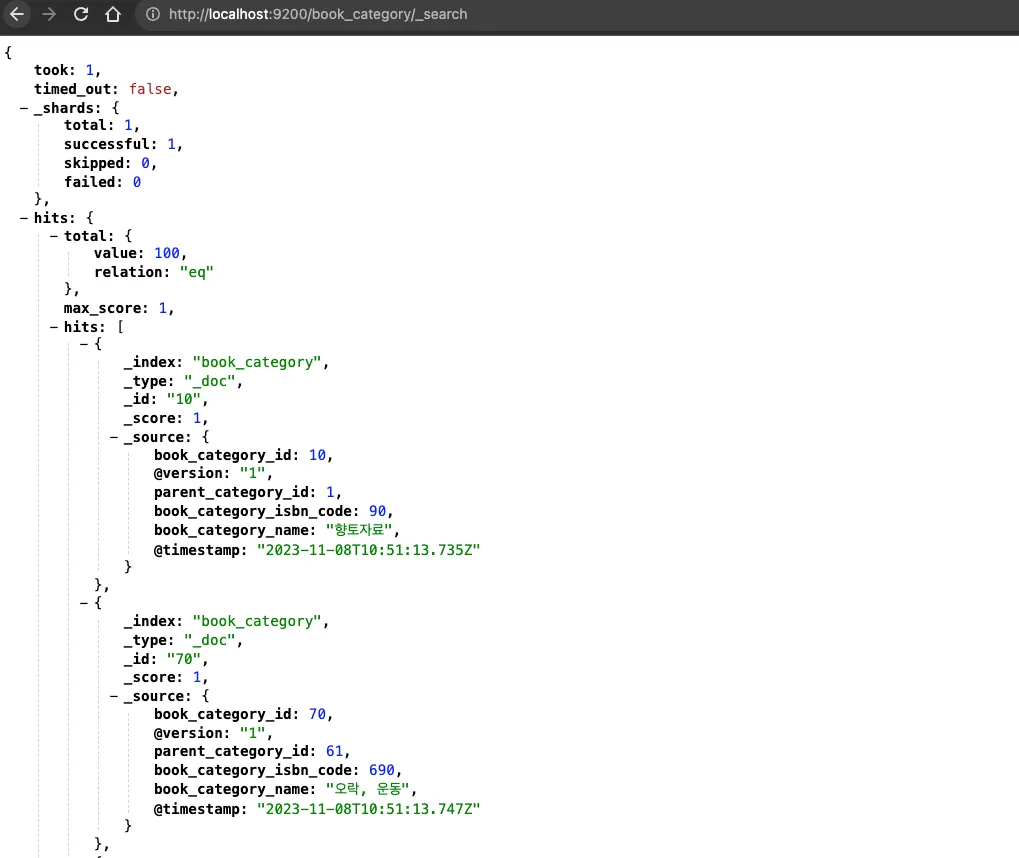
자료의 형태 또한 원하는 방식대로 필드가 구성되고 값들이 입력된 것을 확인 할 수 있었습니다.
EC2와 가상의 RDS로부터 데이터 전달하기
이제 동일한 세팅을 외부→외부 에서 진행하려고 합니다.
MySQL Connector/J 다운로드
EC2 콘솔에서 아래 명령어를 통해 MySQL Connector/J의 최신 버전을 다운로드할 수 있습니다.
wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-8.0.23.tar.gz
Shell
복사
압축을 풀어서 JAR 파일을 얻습니다.
tar -zxvf mysql-connector-java-8.0.23.tar.gz
Shell
복사
MySQL Connector/J를 압축 푼 후에는 JAR 파일이 생성됩니다.
이제 해당 JAR 파일을 Logstash의 /etc/logstash/conf.d/디렉토리로 복사합니다.
sudo cp mysql-connector-java-8.0.23/mysql-connector-java-8.0.23.jar /etc/logstash/conf.d/
Shell
복사
EC2내부에서 /etc/logstash/conf.d/디렉토리로 mysql-connector-java-8.0.23.jar를 복사해두었습니다.

conf파일 작성
Local(외부접속을 열어두어 RDS화 시킴) → EC2(ELK) 를 통한 데이터 전송이 정확하게 진행되는지 확인하기 위해서 해당 conf파일을 작성합니다.
Logstash의 input/output 를 정의하는 사용자 설정 파일인 sampletest2.conf을 만들어보았습니다.
# sampletest2.conf
# 초기 데이터 색인을 위한 input/output 블록
input {
jdbc {
jdbc_connection_string => "jdbc:mysql://{외부IP주소}:3306/team258"
jdbc_user => "inyongkim"
jdbc_password => "1234"
jdbc_driver_library => "/etc/logstash/conf.d/mysql-connector-java-8.0.25.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
# jdbc_paging_enabled => true
# jdbc_page_size => 50000 # JVM 메모리 부하 감당할 수 있는 정도로 설정
# schedule => "* * * * *" # 서버실행시 1회만 실행되도록 주기 제거
statement => "SELECT * FROM book_category"
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "book_category"
document_id => "%{book_category_id}"
}
}
Shell
복사
sudo cp sampletest2.conf /etc/logstash/conf.d/
Shell
복사
여기서 추가적으로 확인해야 하는점은 jdbc_driver_library 의 위치가 EC2에서 직접 다운로드 받은것을 카피한 경로로 변경되어야 하는점입니다.
output의 localhost:9200 은 EC2입장에서 Elasticsearch는 로컬이기 때문에 그대로 두어도 됩니다.
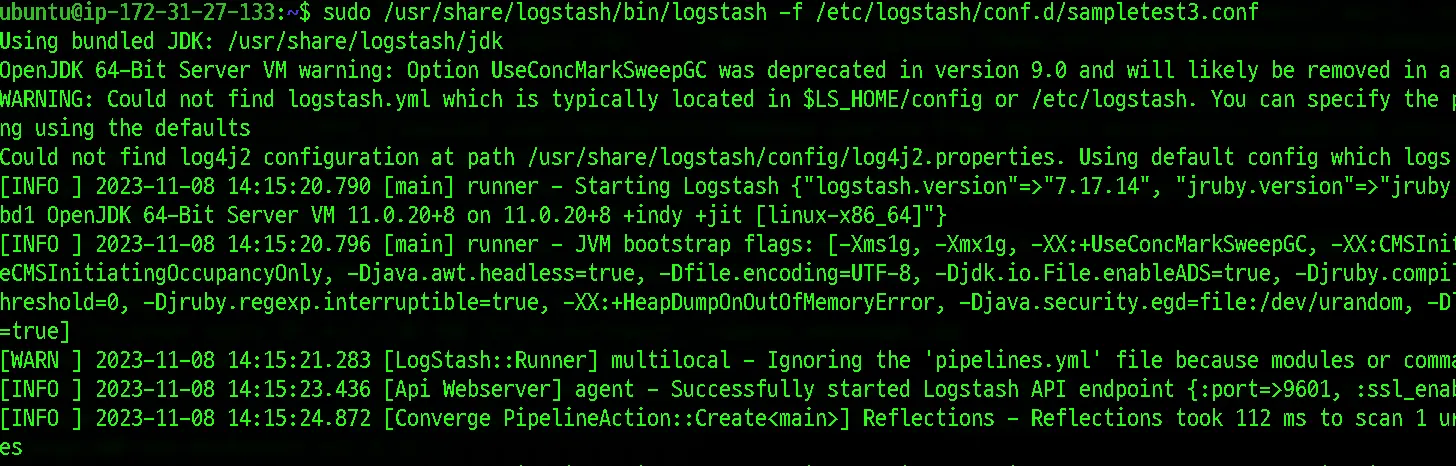
sudo /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/sampletest2.conf
Shell
복사
ELK의 사양의 중요성 (특히, Logstash의 CPU 점유율에 대한 문제)
Logstash로 EC2에서 원격 DB(MySQL)로 데이터를 로드하고 Elasticsearch로 전달하는데 있어서 문제가 발생했습니다. 위 명령문을 실행했음에도 불구하고 EC2 자체가 응답없는 상태가 계속 진행되었고, 해당 문제를 파악하기 위해서 기본적으로 ELK Stack이 차지하는 CPU 및 RAM 점유율을 확인했습니다.

Logstash 설치 경로에 있는 logstash.yml 설정 파일을 살펴보면 기본적으로 Logstash는 2코어로 설정되어 있으며, pipeline.workers: 1 로 설정해도 해당 리소스를 줄일 수 없었고, 따라서 CPU를 확보 할 수 없었습니다.
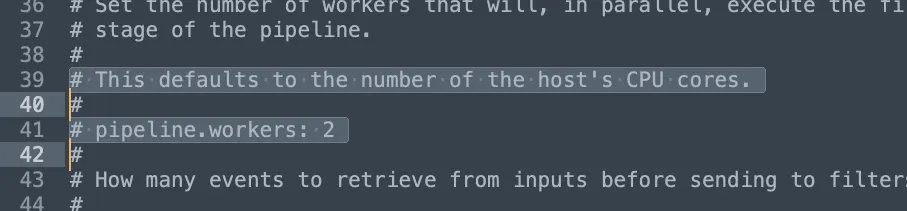
특히 EC2처럼 프리티어로는 2코어정도로 빈약한 서버의 스펙에서는 3개의 ELK 스택 자체를 실행하는 것만 해도 모든 리소스를 사용할 정도이며 Logstash를 통한 데이터 로드, 전달 등에 소모 될 리소스가 없었기 때문에 응답이 없는 상태로 다운되는 현상이 발생한 것입니다.
따라서 Logstash 등 ELK 스택에서 2코어는 최소사양임을 인지하고 EC2 인스턴스 자체를 2core/4GB의 사양인 t2.medium에서 최소사양을 충분히 커버할만한 4core/8GB 사양을 갖춘 c5a.xlarge 로 새로 인스턴스를 생성하고 이전 작업들을 동일하게 진행했습니다.
c5a.xlarge EC2 인스턴스에서의 RDS(MySQL)-Logstash-Elasticsearch 데이터 동기화
logstash의 실행 내용을 정의하는 sampletest3.conf파일은 다음과 같이 수정되었습니다.
•
현재 프로젝트 아키텍처에서 사용중인 AWS RDS(MySQL)로부터 데이터를 로드하게됩니다.
◦
이 부분은 로컬 PC를 외부 접속으로 변경하면서 충분히 IP를 통한 외부 접속으로 데이터를 가져오는 부분이 확인된 상태
•
메모리 부하를 고려하여 페이징으로 10개씩 로드하고 Elasticsearch로 전달합니다. 대상은 MySQL의 book 테이블입니다.
•
기존 테스트 내용들에 따라 필요한 데이터들을 Local(EC2 입장에서는 Local) Elasticsearch에 색인합니다.
# sampletest3.conf
# 초기 데이터 색인을 위한 input/output 블록
input {
jdbc {
jdbc_connection_string => "jdbc:mysql://team258-db.c4zi...zonaws.com:3306/team258_DB"
jdbc_user => "{user}"
jdbc_password => "{pass}"
jdbc_driver_library => "/etc/logstash/conf.d/mysql-connector-java-8.0.23.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_paging_enabled => true
jdbc_page_size => 10 # JVM 메모리 부하 감당할 수 있는 정도로 설정
# schedule => "* * * * *" # 서버실행시 1회만 실행되도록 주기 제거
statement => "SELECT * FROM book"
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "book"
document_id => "%{book_id}"
}
}
Shell
복사
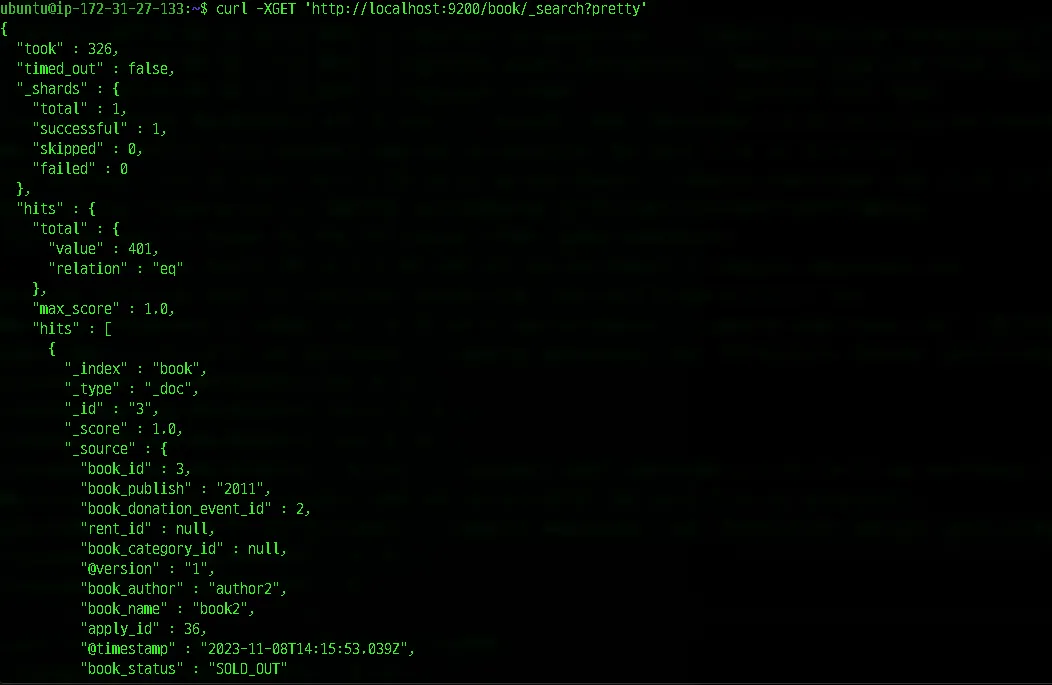
실행 결과 t2.micro에서는 응답없던 데이터 전달이 c5a.xlarge 스케일업을 통해서 최소 사양을 만족하여 정상적으로 작동하고 데이터가 전달되는 것을 확인 할 수 있었습니다.

Elasticsearch내 데이터 조회를 통해서 정상적으로 데이터들이 전달-색인되어 저장 된 것을 확인 할 수 있었습니다.